 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTrax: Embedding Graphs of Financial Transactions
Jul 16, 2019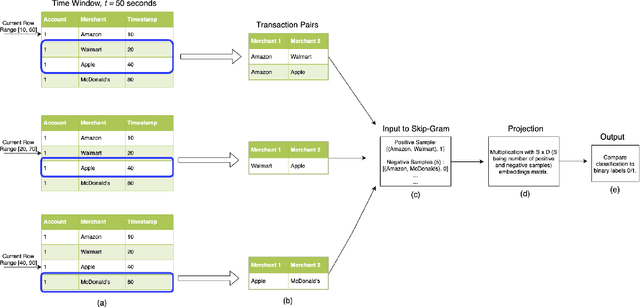
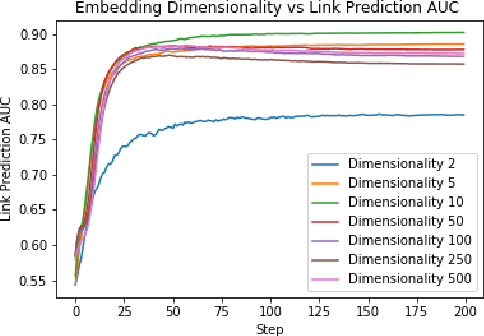
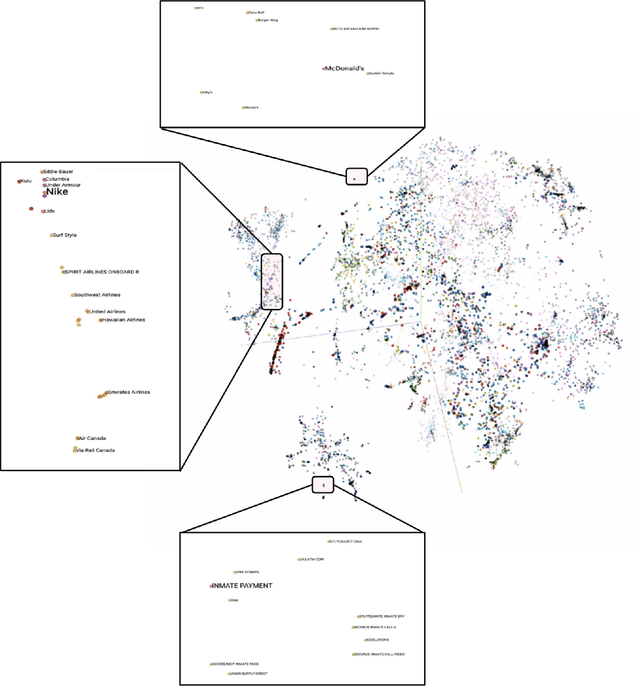
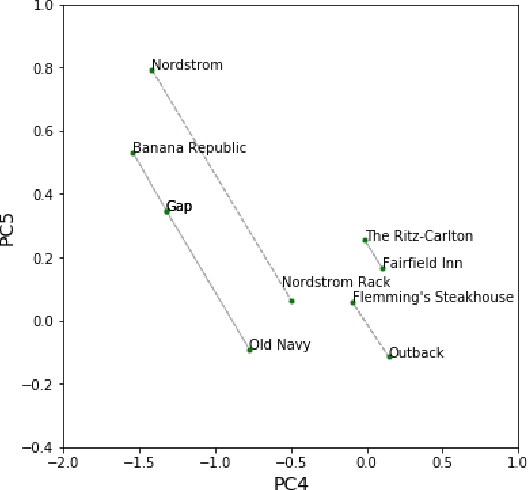
Financial transactions can be considered edges in a heterogeneous graph between entities sending money and entities receiving money. For financial institutions, such a graph is likely large (with millions or billions of edges) while also sparsely connected. It becomes challenging to apply machine learning to such large and sparse graphs. Graph representation learning seeks to embed the nodes of a graph into a Euclidean vector space such that graph topological properties are preserved after the transformation. In this paper, we present a novel application of representation learning to bipartite graphs of credit card transactions in order to learn embeddings of account and merchant entities. Our framework is inspired by popular approaches in graph embeddings and is trained on two internal transaction datasets. This approach yields highly effective embeddings, as quantified by link prediction AUC and F1 score. Further, the resulting entity vectors retain intuitive semantic similarity that is explored through visualizations and other qualitative analyses. Finally, we show how these embeddings can be used as features in downstream machine learning business applications such as fraud detection.
Graph Embeddings at Scale
Jul 03, 2019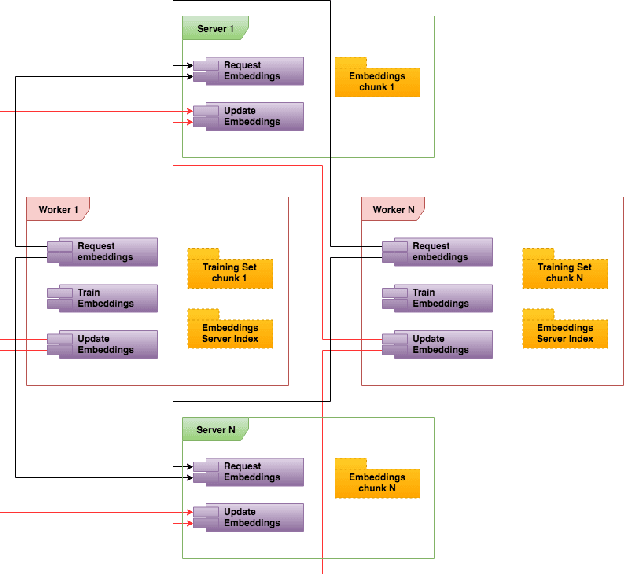

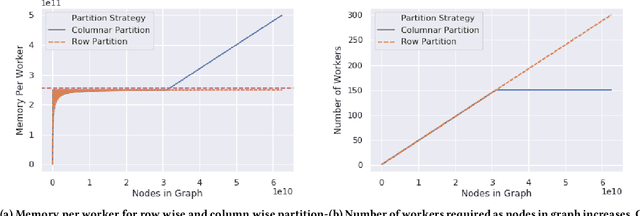

Graph embedding is a popular algorithmic approach for creating vector representations for individual vertices in networks. Training these algorithms at scale is important for creating embeddings that can be used for classification, ranking, recommendation and other common applications in industry. While industrial systems exist for training graph embeddings on large datasets, many of these distributed architectures are forced to partition copious amounts of data and model logic across many worker nodes. In this paper, we propose a distributed infrastructure that completely avoids graph partitioning, dynamically creates size constrained computational graphs across worker nodes, and uses highly efficient indexing operations for updating embeddings that allow the system to function at scale. We show that our system can scale an existing embeddings algorithm - skip-gram - to train on the open-source Friendster network (68 million vertices) and on an internal heterogeneous graph (50 million vertices). We measure the performance of our system on two key quantitative metrics: link-prediction accuracy and rate of convergence. We conclude this work by analyzing how a greater number of worker nodes actually improves our system's performance on the aforementioned metrics and discuss our next steps for rigorously evaluating the embedding vectors produced by our system.