 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Embeddings at Scale
Jul 03, 2019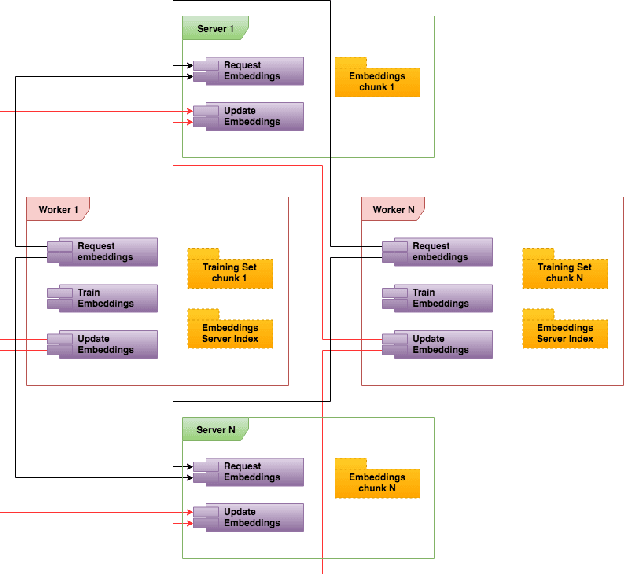

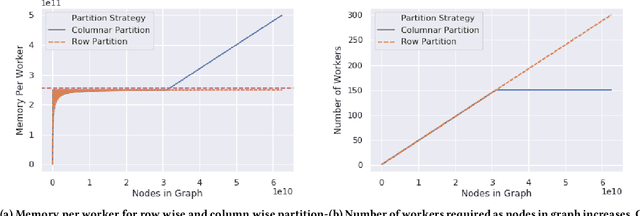

Graph embedding is a popular algorithmic approach for creating vector representations for individual vertices in networks. Training these algorithms at scale is important for creating embeddings that can be used for classification, ranking, recommendation and other common applications in industry. While industrial systems exist for training graph embeddings on large datasets, many of these distributed architectures are forced to partition copious amounts of data and model logic across many worker nodes. In this paper, we propose a distributed infrastructure that completely avoids graph partitioning, dynamically creates size constrained computational graphs across worker nodes, and uses highly efficient indexing operations for updating embeddings that allow the system to function at scale. We show that our system can scale an existing embeddings algorithm - skip-gram - to train on the open-source Friendster network (68 million vertices) and on an internal heterogeneous graph (50 million vertices). We measure the performance of our system on two key quantitative metrics: link-prediction accuracy and rate of convergence. We conclude this work by analyzing how a greater number of worker nodes actually improves our system's performance on the aforementioned metrics and discuss our next steps for rigorously evaluating the embedding vectors produced by our system.
Predicting Online Video Engagement Using Clickstreams
May 20, 2014
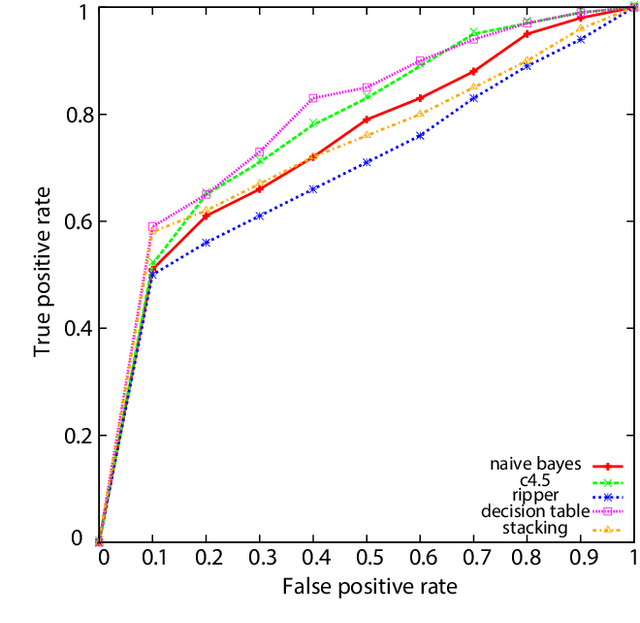


In the nascent days of e-content delivery, having a superior product was enough to give companies an edge against the competition. With today's fiercely competitive market, one needs to be multiple steps ahead, especially when it comes to understanding consumers. Focusing on a large set of web portals owned and managed by a private communications company, we propose methods by which these sites' clickstream data can be used to provide a deep understanding of their visitors, as well as their interests and preferences. We further expand the use of this data to show that it can be effectively used to predict user engagement to video streams.