 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLGNet: A Transformer-based Model for Dialogue Response Generation
Sep 04, 2019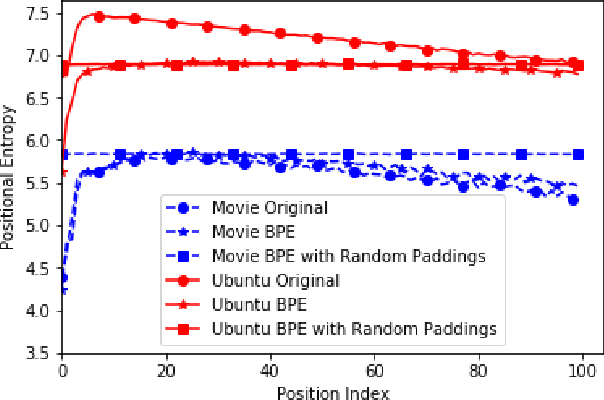

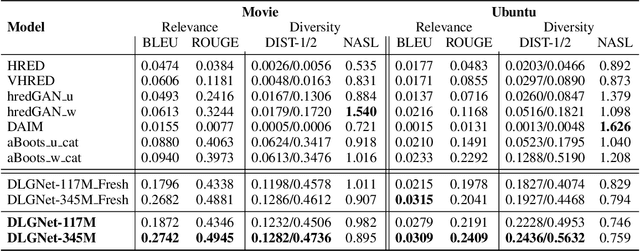
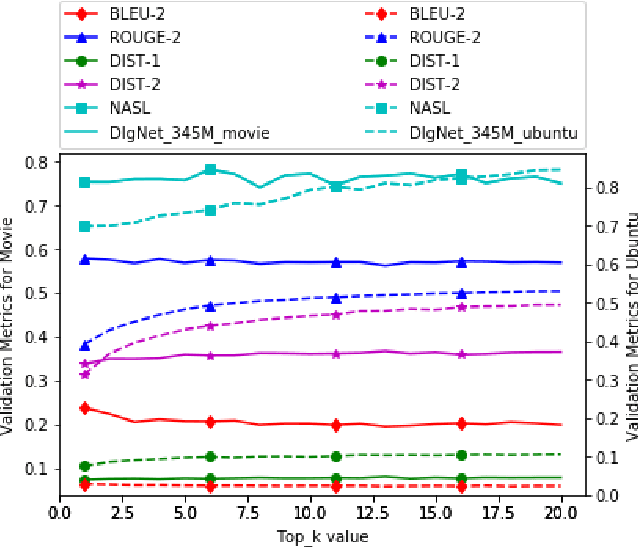
Neural dialogue models, despite their successes, still suffer from lack of relevance, diversity, and in many cases coherence in their generated responses. These issues can attributed to reasons including (1) short-range model architectures that capture limited temporal dependencies, (2) limitations of the maximum likelihood training objective, (3) the concave entropy profile of dialogue datasets resulting in short and generic responses, and (4) the out-of-vocabulary problem leading to generation of a large number of <UNK> tokens. On the other hand, transformer-based models such as GPT-2 have demonstrated an excellent ability to capture long-range structures in language modeling tasks. In this paper, we present DLGNet, a transformer-based model for dialogue modeling. We specifically examine the use of DLGNet for multi-turn dialogue response generation. In our experiments, we evaluate DLGNet on the open-domain Movie Triples dataset and the closed-domain Ubuntu Dialogue dataset. DLGNet models, although trained with only the maximum likelihood objective, achieve significant improvements over state-of-the-art multi-turn dialogue models. They also produce best performance to date on the two datasets based on several metrics, including BLEU, ROUGE, and distinct n-gram. Our analysis shows that the performance improvement is mostly due to the combination of (1) the long-range transformer architecture with (2) the injection of random informative paddings. Other contributing factors include the joint modeling of dialogue context and response, and the 100% tokenization coverage from the byte pair encoding (BPE).
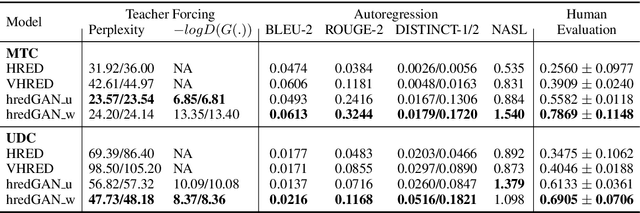
Adversarial Bootstrapping for Dialogue Model Training
Sep 04, 2019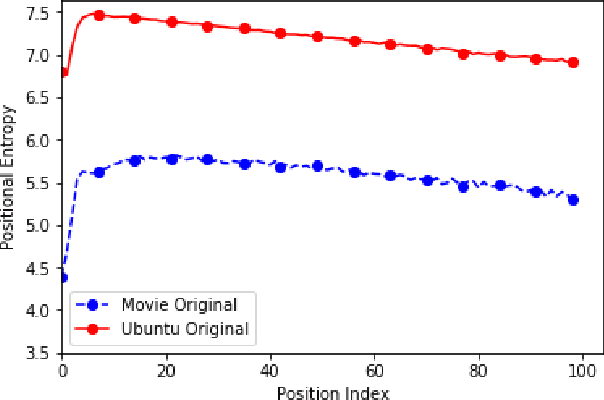
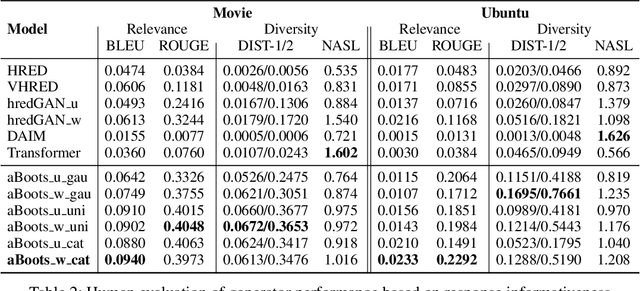
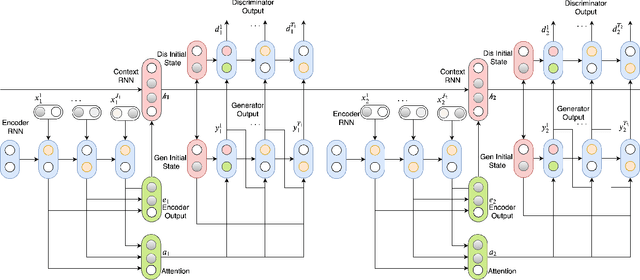
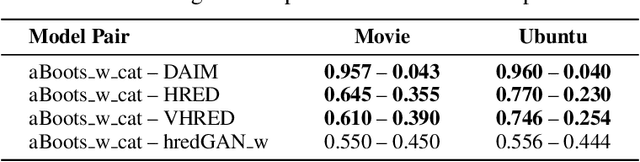
Open domain neural dialogue models, despite their successes, are known to produce responses that lack relevance, diversity, and in many cases coherence. These shortcomings stem from the limited ability of common training objectives to directly express these properties as well as their interplay with training datasets and model architectures. Toward addressing these problems, this paper proposes bootstrapping a dialogue response generator with an adversarially trained discriminator. The method involves training a neural generator in both autoregressive and traditional teacher-forcing modes, with the maximum likelihood loss of the auto-regressive outputs weighted by the score from a metric-based discriminator model. The discriminator input is a mixture of ground truth labels, the teacher-forcing outputs of the generator, and distractors sampled from the dataset, thereby allowing for richer feedback on the autoregressive outputs of the generator. To improve the calibration of the discriminator output, we also bootstrap the discriminator with the matching of the intermediate features of the ground truth and the generator's autoregressive output. We explore different sampling and adversarial policy optimization strategies during training in order to understand how to encourage response diversity without sacrificing relevance. Our experiments shows that adversarial bootstrapping is effective at addressing exposure bias, leading to improvement in response relevance and coherence. The improvement is demonstrated with the state-of-the-art results on the Movie and Ubuntu dialogue datasets with respect to human evaluations and BLUE, ROGUE, and distinct n-gram scores.
An Adversarial Learning Framework For A Persona-Based Multi-Turn Dialogue Model
Apr 29, 2019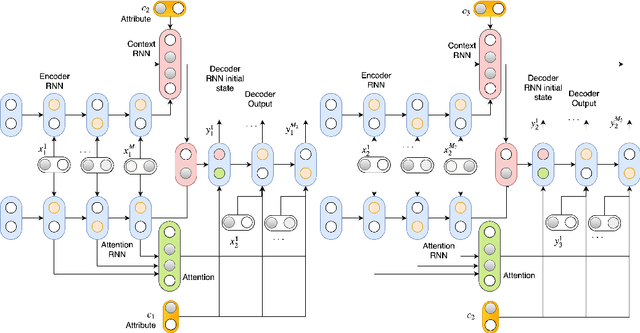
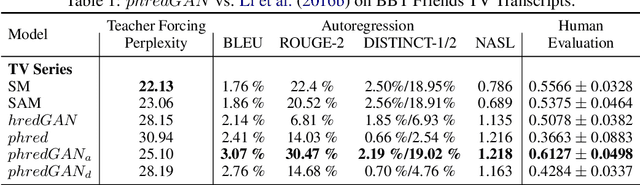
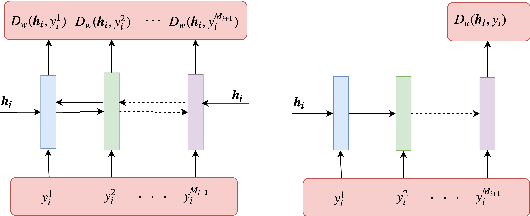
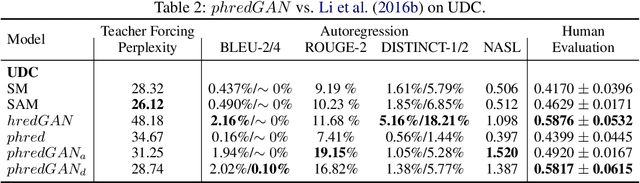
In this paper, we extend the persona-based sequence-to-sequence (Seq2Seq) neural network conversation model to a multi-turn dialogue scenario by modifying the state-of-the-art hredGAN architecture to simultaneously capture utterance attributes such as speaker identity, dialogue topic, speaker sentiments and so on. The proposed system, phredGAN has a persona-based HRED generator (PHRED) and a conditional discriminator. We also explore two approaches to accomplish the conditional discriminator: (1) phredGAN_a, a system that passes the attribute representation as an additional input into a traditional adversarial discriminator, and (2) phredGAN_d, a dual discriminator system which in addition to the adversarial discriminator, collaboratively predicts the attribute(s) that generated the input utterance. To demonstrate the superior performance of phredGAN over the persona Seq2Seq model, we experiment with two conversational datasets, the Ubuntu Dialogue Corpus (UDC) and TV series transcripts from the Big Bang Theory and Friends. Performance comparison is made with respect to a variety of quantitative measures as well as crowd-sourced human evaluation. We also explore the trade-offs from using either variant of phredGAN on datasets with many but weak attribute modalities (such as with Big Bang Theory and Friends) and ones with few but strong attribute modalities (customer-agent interactions in Ubuntu dataset).
A Persona-based Multi-turn Conversation Model in an Adversarial Learning Framework
Apr 29, 2019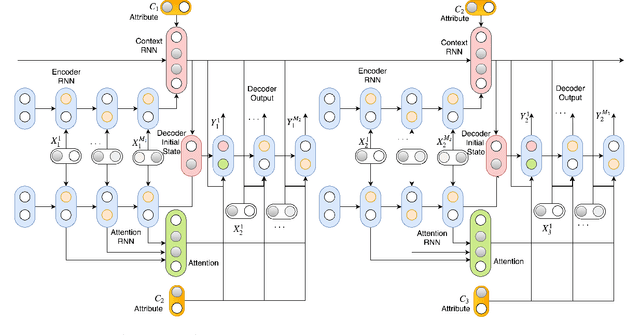

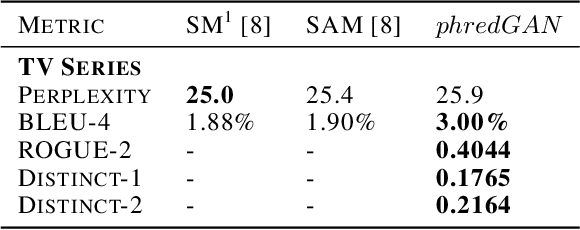

In this paper, we extend the persona-based sequence-to-sequence (Seq2Seq) neural network conversation model to multi-turn dialogue by modifying the state-of-the-art hredGAN architecture. To achieve this, we introduce an additional input modality into the encoder and decoder of hredGAN to capture other attributes such as speaker identity, location, sub-topics, and other external attributes that might be available from the corpus of human-to-human interactions. The resulting persona hredGAN ($phredGAN$) shows better performance than both the existing persona-based Seq2Seq and hredGAN models when those external attributes are available in a multi-turn dialogue corpus. This superiority is demonstrated on TV drama series with character consistency (such as Big Bang Theory and Friends) and customer service interaction datasets such as Ubuntu dialogue corpus in terms of perplexity, BLEU, ROUGE, and Distinct n-gram scores.
Multi-turn Dialogue Response Generation in an Adversarial Learning Framework
Sep 19, 2018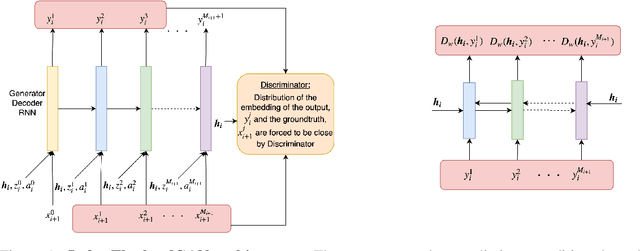
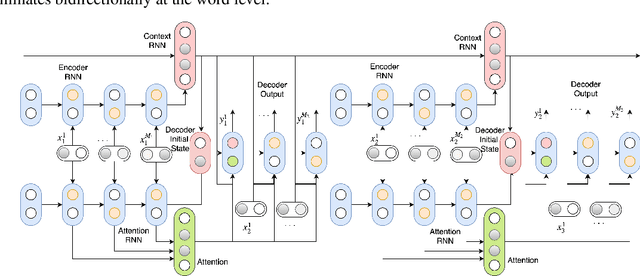
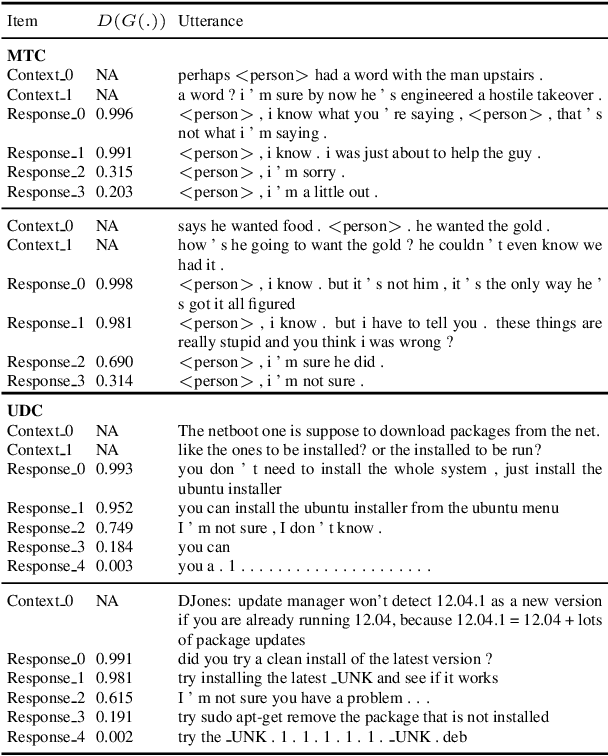
We propose an adversarial learning approach to the generation of multi-turn dialogue responses. Our proposed framework, hredGAN, is based on conditional generative adversarial networks (GANs). The GAN's generator is a modified hierarchical recurrent encoder-decoder network (HRED) and the discriminator is a word-level bidirectional RNN that shares context and word embedding with the generator. During inference, noise samples conditioned on the dialogue history are used to perturb the generator's latent space to generate several possible responses. The final response is the one ranked best by the discriminator. The hredGAN shows major advantages over existing methods: (1) it generalizes better than networks trained using only the log-likelihood criterion, and (2) it generates longer, more informative and more diverse responses with high utterance and topic relevance even with limited training data. This superiority is demonstrated on the Movie triples and Ubuntu dialogue datasets in terms of perplexity, BLEU, ROUGE and Distinct n-gram scores.
Using Thought-Provoking Children's Questions to Drive Artificial Intelligence Research
Jul 26, 2017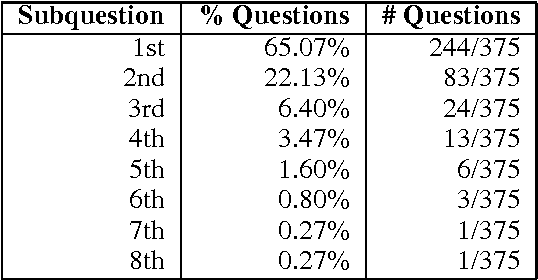
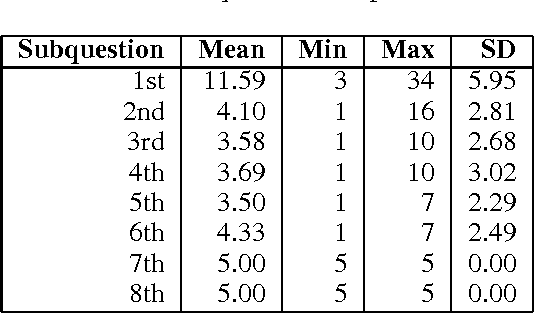

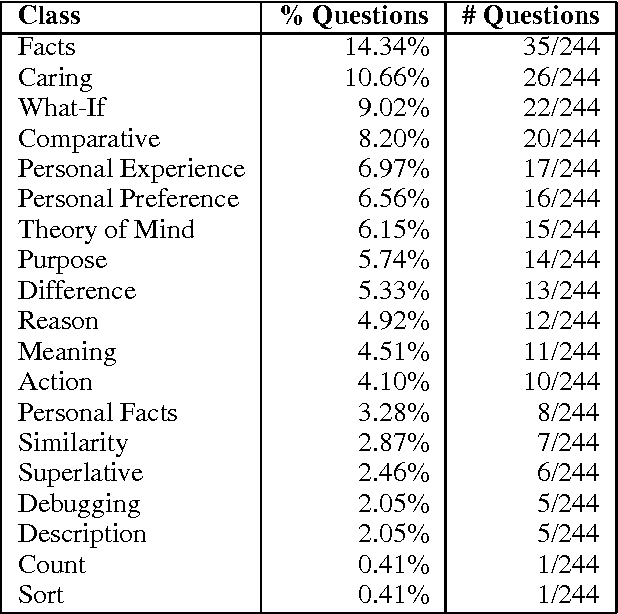
We propose to use thought-provoking children's questions (TPCQs), namely Highlights BrainPlay questions, as a new method to drive artificial intelligence research and to evaluate the capabilities of general-purpose AI systems. These questions are designed to stimulate thought and learning in children, and they can be used to do the same thing in AI systems, while demonstrating the system's reasoning capabilities to the evaluator. We introduce the TPCQ task, which which takes a TPCQ question as input and produces as output (1) answers to the question and (2) learned generalizations. We discuss how BrainPlay questions stimulate learning. We analyze 244 BrainPlay questions, and we report statistics on question type, question class, answer cardinality, answer class, types of knowledge needed, and types of reasoning needed. We find that BrainPlay questions span many aspects of intelligence. Because the answers to BrainPlay questions and the generalizations learned from them are often highly open-ended, we suggest using human judges for evaluation.
Reasoning about RoboCup Soccer Narratives
Feb 14, 2012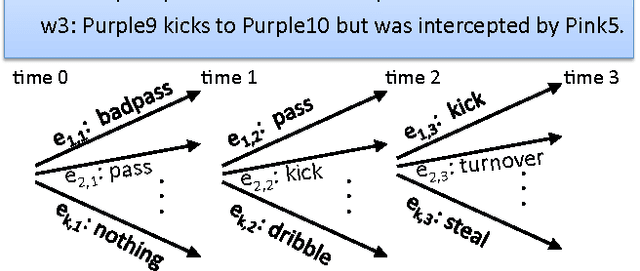
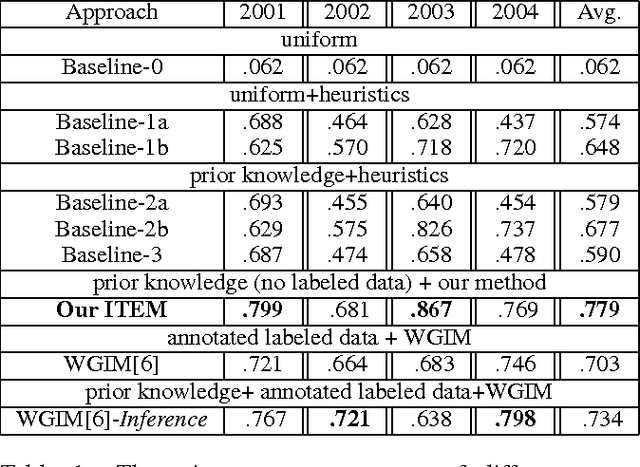


This paper presents an approach for learning to translate simple narratives, i.e., texts (sequences of sentences) describing dynamic systems, into coherent sequences of events without the need for labeled training data. Our approach incorporates domain knowledge in the form of preconditions and effects of events, and we show that it outperforms state-of-the-art supervised learning systems on the task of reconstructing RoboCup soccer games from their commentaries.
A database and lexicon of scripts for ThoughtTreasure
Mar 01, 2000Since scripts were proposed in the 1970's as an inferencing mechanism for AI and natural language processing programs, there have been few attempts to build a database of scripts. This paper describes a database and lexicon of scripts that has been added to the ThoughtTreasure commonsense platform. The database provides the following information about scripts: sequence of events, roles, props, entry conditions, results, goals, emotions, places, duration, frequency, and cost. English and French words and phrases are linked to script concepts.
Prospects for in-depth story understanding by computer
Mar 01, 2000While much research on the hard problem of in-depth story understanding by computer was performed starting in the 1970s, interest shifted in the 1990s to information extraction and word sense disambiguation. Now that a degree of success has been achieved on these easier problems, I propose it is time to return to in-depth story understanding. In this paper I examine the shift away from story understanding, discuss some of the major problems in building a story understanding system, present some possible solutions involving a set of interacting understanding agents, and provide pointers to useful tools and resources for building story understanding systems.
Towards a computational theory of human daydreaming
Dec 10, 1998This paper examines the phenomenon of daydreaming: spontaneously recalling or imagining personal or vicarious experiences in the past or future. The following important roles of daydreaming in human cognition are postulated: plan preparation and rehearsal, learning from failures and successes, support for processes of creativity, emotion regulation, and motivation. A computational theory of daydreaming and its implementation as the program DAYDREAMER are presented. DAYDREAMER consists of 1) a scenario generator based on relaxed planning, 2) a dynamic episodic memory of experiences used by the scenario generator, 3) a collection of personal goals and control goals which guide the scenario generator, 4) an emotion component in which daydreams initiate, and are initiated by, emotional states arising from goal outcomes, and 5) domain knowledge of interpersonal relations and common everyday occurrences. The role of emotions and control goals in daydreaming is discussed. Four control goals commonly used in guiding daydreaming are presented: rationalization, failure/success reversal, revenge, and preparation. The role of episodic memory in daydreaming is considered, including how daydreamed information is incorporated into memory and later used. An initial version of DAYDREAMER which produces several daydreams (in English) is currently running.