 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling in Marathi
Feb 04, 2025While topic modeling in English has become a prevalent and well-explored area, venturing into topic modeling for Indic languages remains relatively rare. The limited availability of resources, diverse linguistic structures, and unique challenges posed by Indic languages contribute to the scarcity of research and applications in this domain. Despite the growing interest in natural language processing and machine learning, there exists a noticeable gap in the comprehensive exploration of topic modeling methodologies tailored specifically for languages such as Hindi, Marathi, Tamil, and others. In this paper, we examine several topic modeling approaches applied to the Marathi language. Specifically, we compare various BERT and non-BERT approaches, including multilingual and monolingual BERT models, using topic coherence and topic diversity as evaluation metrics. Our analysis provides insights into the performance of these approaches for Marathi language topic modeling. The key finding of the paper is that BERTopic, when combined with BERT models trained on Indic languages, outperforms LDA in terms of topic modeling performance.
Recent advances in content based video copy detection
Oct 28, 2016

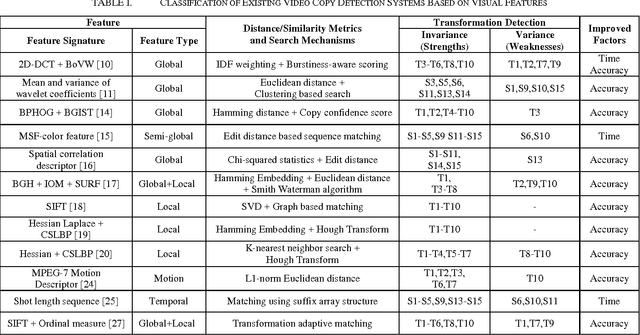

With the immense number of videos being uploaded to the video sharing sites, issue of copyright infringement arises with uploading of illicit copies or transformed versions of original video. Thus safeguarding copyright of digital media has become matter of concern. To address this concern, it is obliged to have a video copy detection system which is sufficiently robust to detect these transformed videos with ability to pinpoint location of copied segments. This paper outlines recent advancement in content based video copy detection, mainly focusing on different visual features employed by video copy detection systems. Finally we evaluate performance of existing video copy detection systems.