 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Teacher Is Worth A Million Instructions
Jun 27, 2024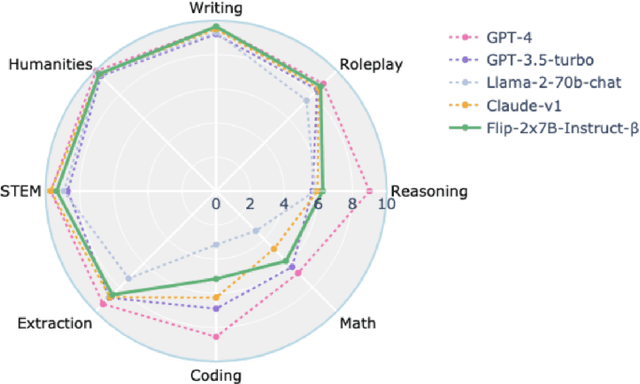
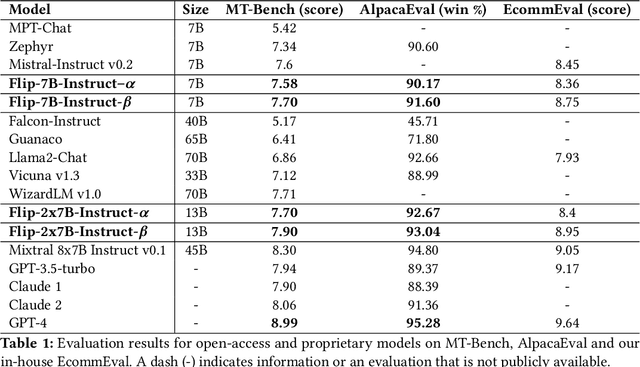
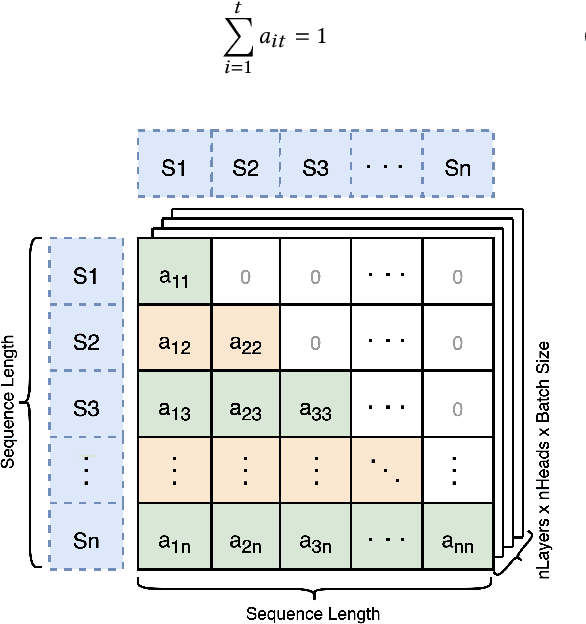
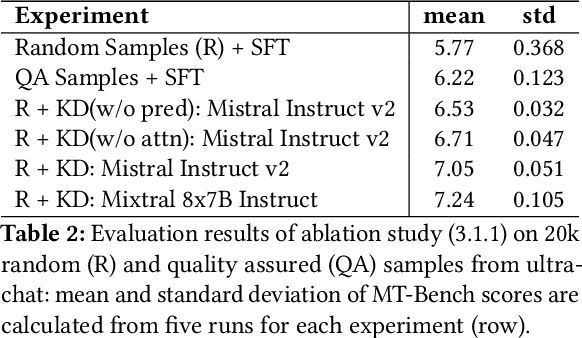
Large Language Models(LLMs) have shown exceptional abilities, yet training these models can be quite challenging. There is a strong dependence on the quality of data and finding the best instruction tuning set. Further, the inherent limitations in training methods create substantial difficulties to train relatively smaller models with 7B and 13B parameters. In our research, we suggest an improved training method for these models by utilising knowledge from larger models, such as a mixture of experts (8x7B) architectures. The scale of these larger models allows them to capture a wide range of variations from data alone, making them effective teachers for smaller models. Moreover, we implement a novel post-training domain alignment phase that employs domain-specific expert models to boost domain-specific knowledge during training while preserving the model's ability to generalise. Fine-tuning Mistral 7B and 2x7B with our method surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to $7.9$ in MT-Bench and $93.04\%$ on AlpacaEval.