 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Teacher Is Worth A Million Instructions
Jun 27, 2024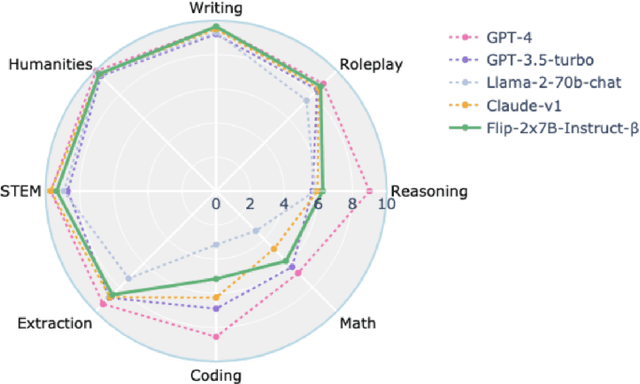
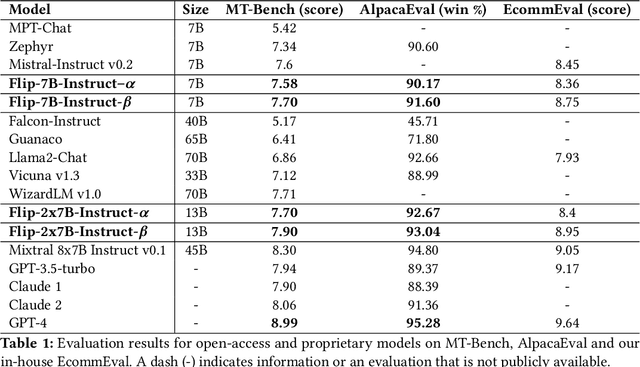
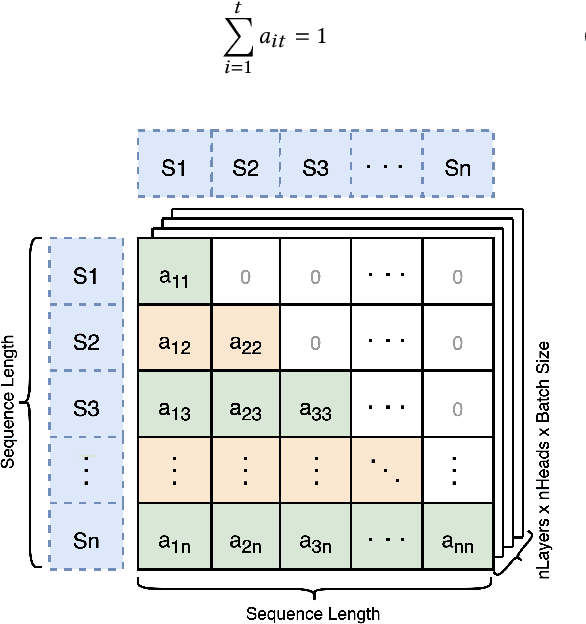
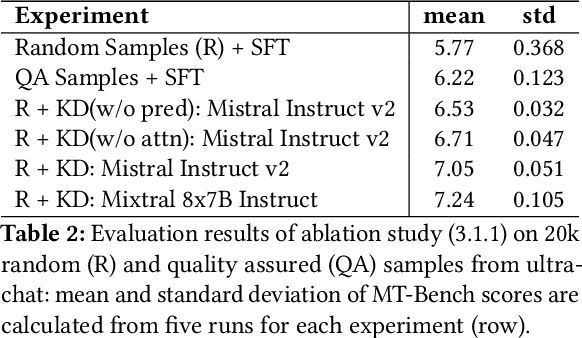
Large Language Models(LLMs) have shown exceptional abilities, yet training these models can be quite challenging. There is a strong dependence on the quality of data and finding the best instruction tuning set. Further, the inherent limitations in training methods create substantial difficulties to train relatively smaller models with 7B and 13B parameters. In our research, we suggest an improved training method for these models by utilising knowledge from larger models, such as a mixture of experts (8x7B) architectures. The scale of these larger models allows them to capture a wide range of variations from data alone, making them effective teachers for smaller models. Moreover, we implement a novel post-training domain alignment phase that employs domain-specific expert models to boost domain-specific knowledge during training while preserving the model's ability to generalise. Fine-tuning Mistral 7B and 2x7B with our method surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to $7.9$ in MT-Bench and $93.04\%$ on AlpacaEval.
L3Cube-HingCorpus and HingBERT: A Code Mixed Hindi-English Dataset and BERT Language Models
Apr 18, 2022


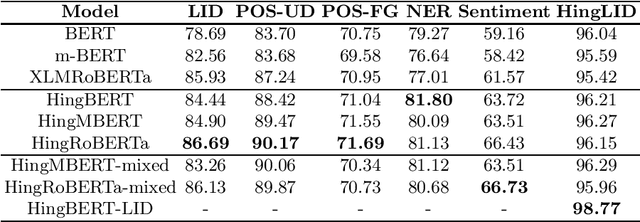
Code-switching occurs when more than one language is mixed in a given sentence or a conversation. This phenomenon is more prominent on social media platforms and its adoption is increasing over time. Therefore code-mixed NLP has been extensively studied in the literature. As pre-trained transformer-based architectures are gaining popularity, we observe that real code-mixing data are scarce to pre-train large language models. We present L3Cube-HingCorpus, the first large-scale real Hindi-English code mixed data in a Roman script. It consists of 52.93M sentences and 1.04B tokens, scraped from Twitter. We further present HingBERT, HingMBERT, HingRoBERTa, and HingGPT. The BERT models have been pre-trained on codemixed HingCorpus using masked language modelling objectives. We show the effectiveness of these BERT models on the subsequent downstream tasks like code-mixed sentiment analysis, POS tagging, NER, and LID from the GLUECoS benchmark. The HingGPT is a GPT2 based generative transformer model capable of generating full tweets. We also release L3Cube-HingLID Corpus, the largest code-mixed Hindi-English language identification(LID) dataset and HingBERT-LID, a production-quality LID model to facilitate capturing of more code-mixed data using the process outlined in this work. The dataset and models are available at https://github.com/l3cube-pune/code-mixed-nlp .
Contextual Hate Speech Detection in Code Mixed Text using Transformer Based Approaches
Nov 01, 2021


In the recent past, social media platforms have helped people in connecting and communicating to a wider audience. But this has also led to a drastic increase in cyberbullying. It is essential to detect and curb hate speech to keep the sanity of social media platforms. Also, code mixed text containing more than one language is frequently used on these platforms. We, therefore, propose automated techniques for hate speech detection in code mixed text from scraped Twitter. We specifically focus on code mixed English-Hindi text and transformer-based approaches. While regular approaches analyze the text independently, we also make use of content text in the form of parent tweets. We try to evaluate the performances of multilingual BERT and Indic-BERT in single-encoder and dual-encoder settings. The first approach is to concatenate the target text and context text using a separator token and get a single representation from the BERT model. The second approach encodes the two texts independently using a dual BERT encoder and the corresponding representations are averaged. We show that the dual-encoder approach using independent representations yields better performance. We also employ simple ensemble methods to further improve the performance. Using these methods we report the best F1 score of 73.07% on the HASOC 2021 ICHCL code mixed data set.