 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Targeting: an incremental learning approach for data imbalance in text classification
Nov 23, 2020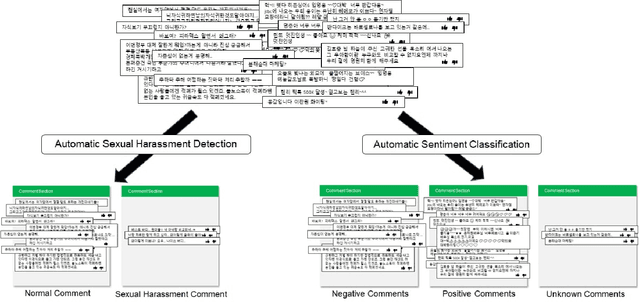
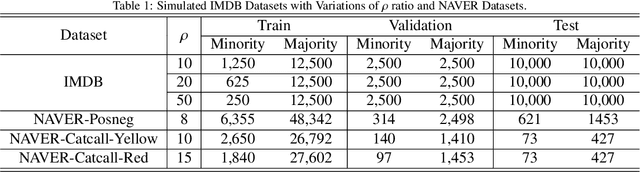
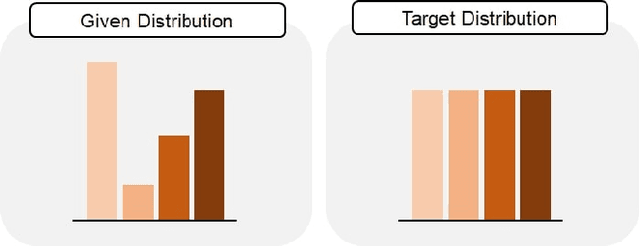
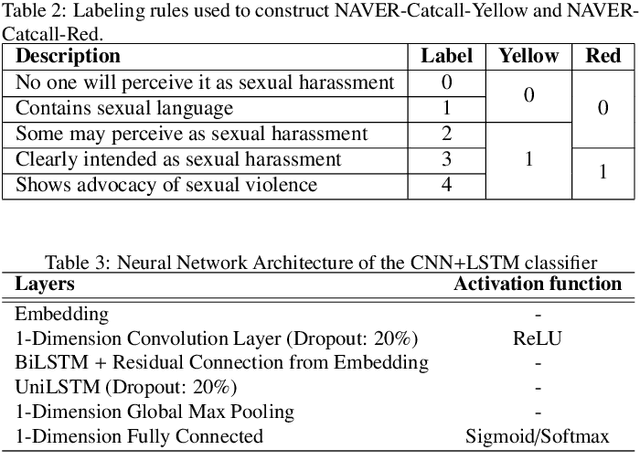
Classification tasks require a balanced distribution of data to ensure the learner to be trained to generalize over all classes. In real-world datasets, however, the number of instances vary substantially among classes. This typically leads to a learner that promotes bias towards the majority group due to its dominating property. Therefore, methods to handle imbalanced datasets are crucial for alleviating distributional skews and fully utilizing the under-represented data, especially in text classification. While addressing the imbalance in text data, most methods utilize sampling methods on the numerical representation of the data, which limits its efficiency on how effective the representation is. We propose a novel training method, Sequential Targeting(ST), independent of the effectiveness of the representation method, which enforces an incremental learning setting by splitting the data into mutually exclusive subsets and training the learner adaptively. To address problems that arise within incremental learning, we apply elastic weight consolidation. We demonstrate the effectiveness of our method through experiments on simulated benchmark datasets (IMDB) and data collected from NAVER.