 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Relaxed Quantization with DropBits: Training Low-Bit Neural Networks via Bit-wise Regularization
Paper and Code
Nov 29, 2019
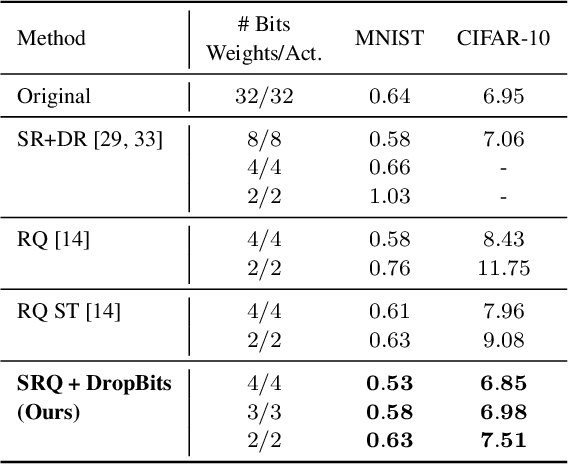
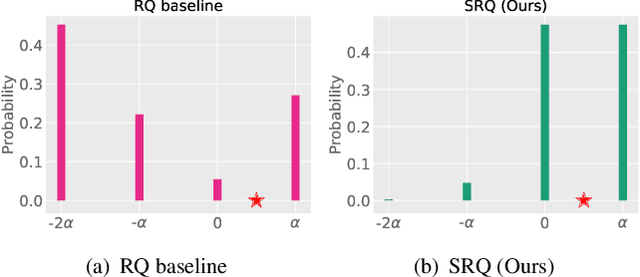
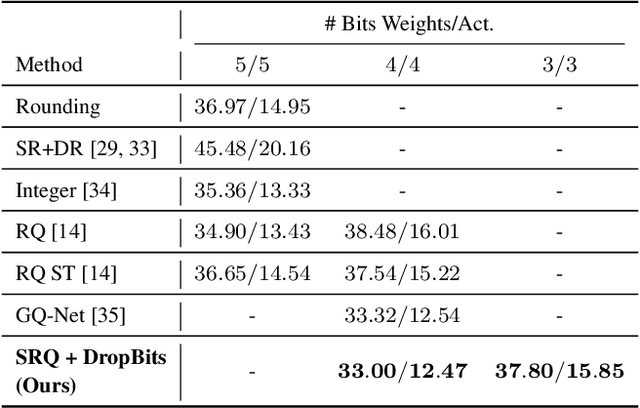
Neural Network quantization, which aims to reduce bit-lengths of the network weights and activations, is one of the key ingredients to reduce the size of neural networks for their deployments to resource-limited devices. However, compressing to low bit-lengths may incur large loss of information and preserving the performance of the full-precision networks under these settings is extremely challenging even with the state-of-the-art quantization approaches. To tackle this problem of low-bit quantization, we propose a novel Semi-Relaxed Quantization (SRQ) that can effectively reduce the quantization error, along with a new regularization technique, DropBits which replaces dropout regularization to randomly drop the bits instead of neurons to minimize information loss while improving generalization on low-bit networks. Moreover, we show the possibility of learning heterogeneous quantization levels, that finds proper bit-lengths for each layer using DropBits. We experimentally validate our method on various benchmark datasets and network architectures, whose results show that our method largely outperforms recent quantization approaches. To the best of our knowledge, we are the first in obtaining competitive performance on 3-bit quantization of ResNet-18 on ImageNet dataset with both weights and activations quantized, across all layers. Last but not the least, we show promising results on heterogeneous quantization, which we believe will open the door to new research directions in neural network quantization.