 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Family of Stochastic Proximal Gradient Methods for Deep Learning
Paper and Code
Jul 15, 2020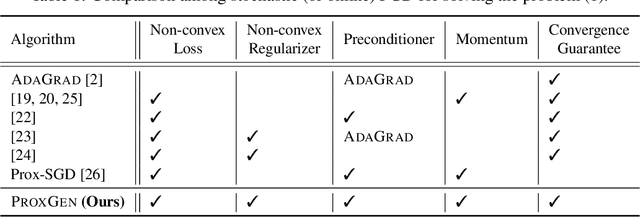
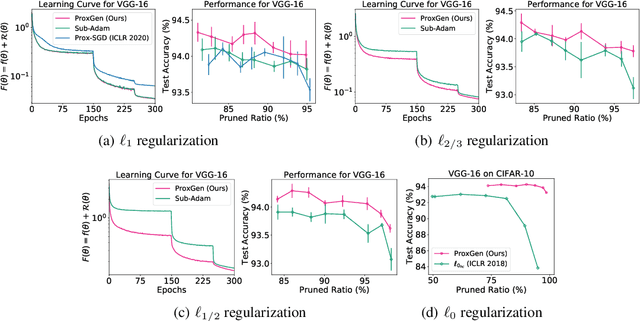

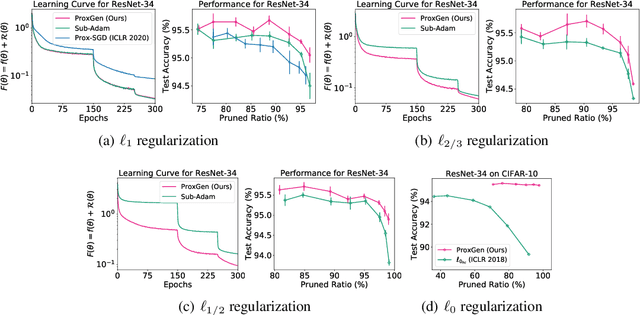
We study the training of regularized neural networks where the regularizer can be non-smooth and non-convex. We propose a unified framework for stochastic proximal gradient descent, which we term ProxGen, that allows for arbitrary positive preconditioners and lower semi-continuous regularizers. Our framework encompasses standard stochastic proximal gradient methods without preconditioners as special cases, which have been extensively studied in various settings. Not only that, we present two important update rules beyond the well-known standard methods as a byproduct of our approach: (i) the first closed-form proximal mappings of $\ell_q$ regularization ($0 \leq q \leq 1$) for adaptive stochastic gradient methods, and (ii) a revised version of ProxQuant that fixes a caveat of the original approach for quantization-specific regularizers. We analyze the convergence of ProxGen and show that the whole family of ProxGen enjoys the same convergence rate as stochastic proximal gradient descent without preconditioners. We also empirically show the superiority of proximal methods compared to subgradient-based approaches via extensive experiments. Interestingly, our results indicate that proximal methods with non-convex regularizers are more effective than those with convex regularizers.