 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
Paper and Code
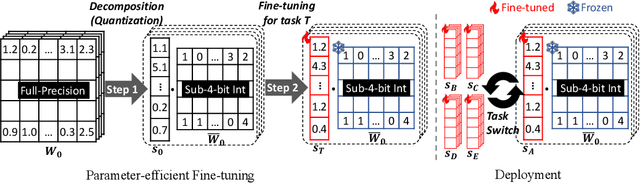

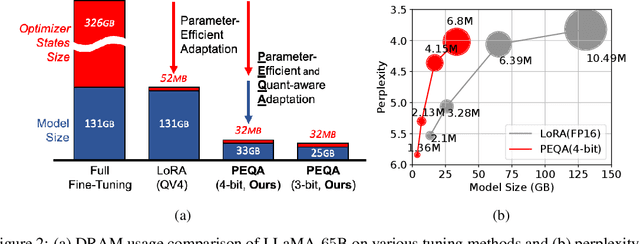
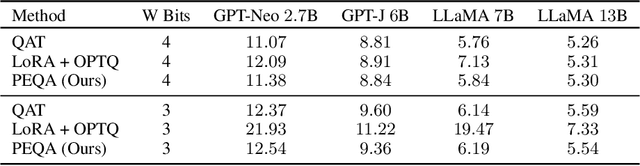
Parameter-efficient fine-tuning (PEFT) methods have emerged to mitigate the prohibitive cost of full fine-tuning large language models (LLMs). Nonetheless, the enormous size of LLMs impedes routine deployment. To address the issue, we present Parameter-Efficient and Quantization-aware Adaptation (PEQA), a novel quantization-aware PEFT technique that facilitates model compression and accelerates inference. PEQA operates through a dual-stage process: initially, the parameter matrix of each fully-connected layer undergoes quantization into a matrix of low-bit integers and a scalar vector; subsequently, fine-tuning occurs on the scalar vector for each downstream task. Such a strategy compresses the size of the model considerably, leading to a lower inference latency upon deployment and a reduction in the overall memory required. At the same time, fast fine-tuning and efficient task switching becomes possible. In this way, PEQA offers the benefits of quantization, while inheriting the advantages of PEFT. We compare PEQA with competitive baselines in comprehensive experiments ranging from natural language understanding to generation benchmarks. This is done using large language models of up to $65$ billion parameters, demonstrating PEQA's scalability, task-specific adaptation performance, and ability to follow instructions, even in extremely low-bit settings.