 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework for Learning Stochastic Representations for Sequence Generation and Recognition
Dec 30, 2024



The ability to generate and recognize sequential data is fundamental for autonomous systems operating in dynamic environments. Inspired by the key principles of the brain-predictive coding and the Bayesian brain-we propose a novel stochastic Recurrent Neural Network with Parametric Biases (RNNPB). The proposed model incorporates stochasticity into the latent space using the reparameterization trick used in variational autoencoders. This approach enables the model to learn probabilistic representations of multidimensional sequences, capturing uncertainty and enhancing robustness against overfitting. We tested the proposed model on a robotic motion dataset to assess its performance in generating and recognizing temporal patterns. The experimental results showed that the stochastic RNNPB model outperformed its deterministic counterpart in generating and recognizing motion sequences. The results highlighted the proposed model's capability to quantify and adjust uncertainty during both learning and inference. The stochasticity resulted in a continuous latent space representation, facilitating stable motion generation and enhanced generalization when recognizing novel sequences. Our approach provides a biologically inspired framework for modeling temporal patterns and advances the development of robust and adaptable systems in artificial intelligence and robotics.
Modeling Financial Time Series using LSTM with Trainable Initial Hidden States
Jul 14, 2020
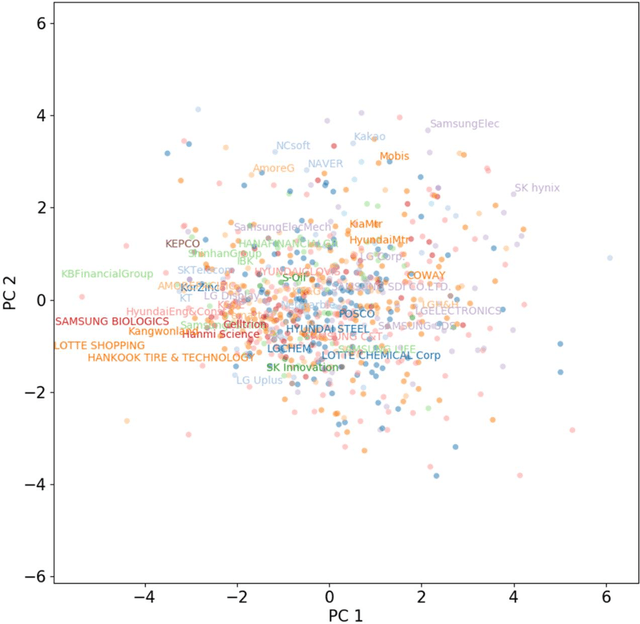


Extracting previously unknown patterns and information in time series is central to many real-world applications. In this study, we introduce a novel approach to modeling financial time series using a deep learning model. We use a Long Short-Term Memory (LSTM) network equipped with the trainable initial hidden states. By learning to reconstruct time series, the proposed model can represent high-dimensional time series data with its parameters. An experiment with the Korean stock market data showed that the model was able to capture the relative similarity between a large number of stock prices in its latent space. Besides, the model was also able to predict the future stock trends from the latent space. The proposed method can help to identify relationships among many time series, and it could be applied to financial applications, such as optimizing the investment portfolios.
A Neurorobotics Approach to Investigating the Emergence of Communication in Robots
Apr 05, 2019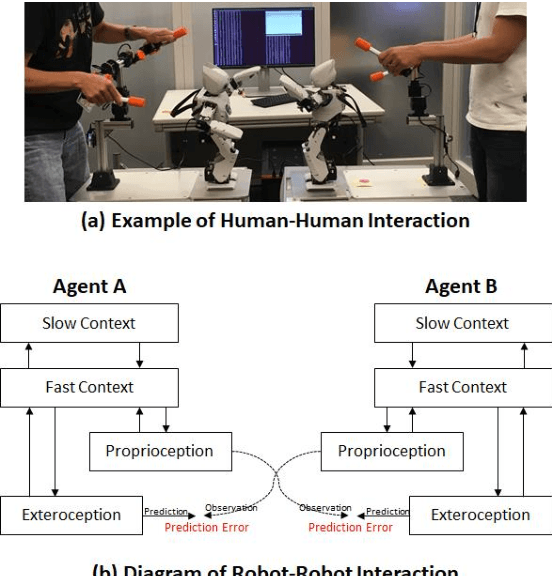
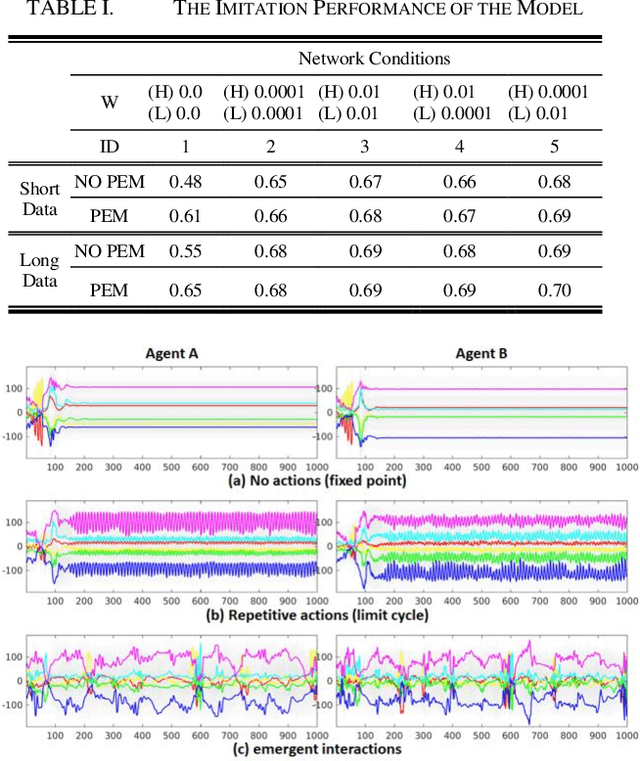
This paper introduces our approach to building a robot with communication capability based on the two key features: stochastic neural dynamics and prediction error minimization (PEM). A preliminary experiment with humanoid robots showed that the robot was able to imitate other's action by means of those key features. In addition, we found that some sorts of communicative patterns emerged between two robots in which the robots inferred the intention of another agent behind the sensory observation.
A Dynamic Neural Network Approach to Generating Robot's Novel Actions: A Simulation Experiment
May 15, 2018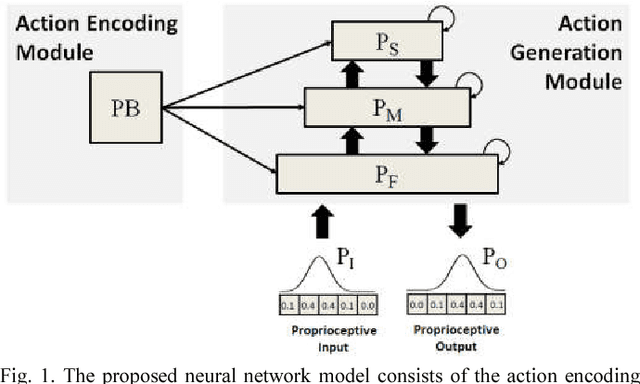



In this study, we investigate how a robot can generate novel and creative actions from its own experience of learning basic actions. Inspired by a machine learning approach to computational creativity, we propose a dynamic neural network model that can learn and generate robot's actions. We conducted a set of simulation experiments with a humanoid robot. The results showed that the proposed model was able to learn the basic actions and also to generate novel actions by modulating and combining those learned actions. The analysis on the neural activities illustrated that the ability to generate creative actions emerged from the model's nonlinear memory structure self-organized during training. The results also showed that the different way of learning the basic actions induced the self-organization of the memory structure with the different characteristics, resulting in the generation of different levels of creative actions. Our approach can be utilized in human-robot interaction in which a user can interactively explore the robot's memory to control its behavior and also discover other novel actions.
Predictive Coding-based Deep Dynamic Neural Network for Visuomotor Learning
Jun 08, 2017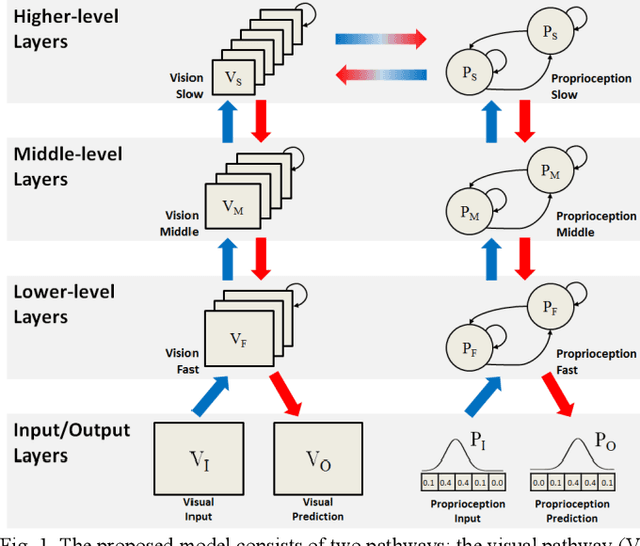
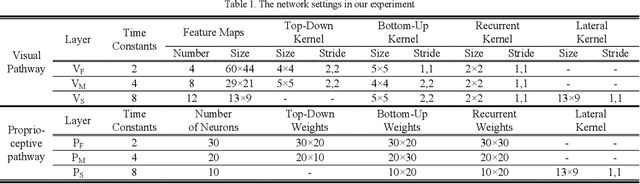
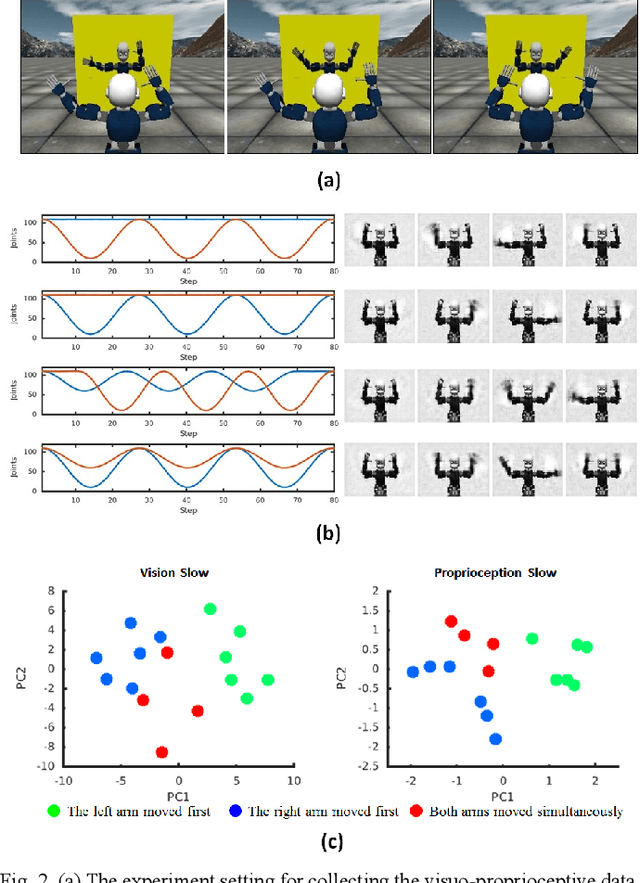
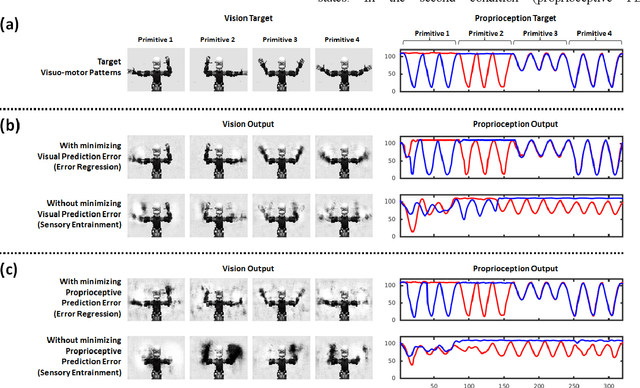
This study presents a dynamic neural network model based on the predictive coding framework for perceiving and predicting the dynamic visuo-proprioceptive patterns. In our previous study [1], we have shown that the deep dynamic neural network model was able to coordinate visual perception and action generation in a seamless manner. In the current study, we extended the previous model under the predictive coding framework to endow the model with a capability of perceiving and predicting dynamic visuo-proprioceptive patterns as well as a capability of inferring intention behind the perceived visuomotor information through minimizing prediction error. A set of synthetic experiments were conducted in which a robot learned to imitate the gestures of another robot in a simulation environment. The experimental results showed that with given intention states, the model was able to mentally simulate the possible incoming dynamic visuo-proprioceptive patterns in a top-down process without the inputs from the external environment. Moreover, the results highlighted the role of minimizing prediction error in inferring underlying intention of the perceived visuo-proprioceptive patterns, supporting the predictive coding account of the mirror neuron systems. The results also revealed that minimizing prediction error in one modality induced the recall of the corresponding representation of another modality acquired during the consolidative learning of raw-level visuo-proprioceptive patterns.
Seamless Integration and Coordination of Cognitive Skills in Humanoid Robots: A Deep Learning Approach
Jun 08, 2017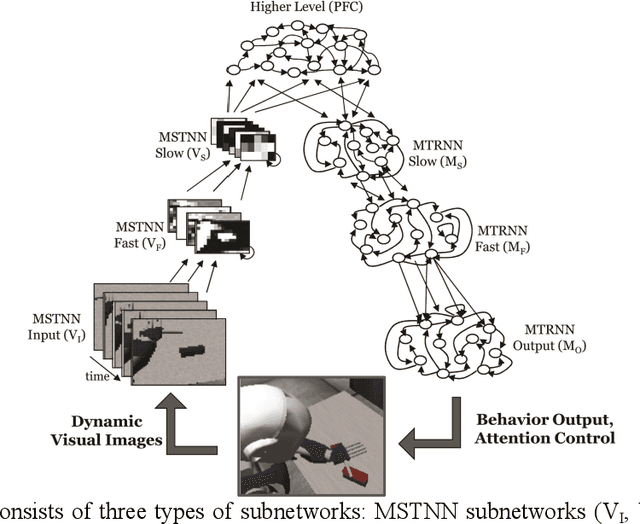


This study investigates how adequate coordination among the different cognitive processes of a humanoid robot can be developed through end-to-end learning of direct perception of visuomotor stream. We propose a deep dynamic neural network model built on a dynamic vision network, a motor generation network, and a higher-level network. The proposed model was designed to process and to integrate direct perception of dynamic visuomotor patterns in a hierarchical model characterized by different spatial and temporal constraints imposed on each level. We conducted synthetic robotic experiments in which a robot learned to read human's intention through observing the gestures and then to generate the corresponding goal-directed actions. Results verify that the proposed model is able to learn the tutored skills and to generalize them to novel situations. The model showed synergic coordination of perception, action and decision making, and it integrated and coordinated a set of cognitive skills including visual perception, intention reading, attention switching, working memory, action preparation and execution in a seamless manner. Analysis reveals that coherent internal representations emerged at each level of the hierarchy. Higher-level representation reflecting actional intention developed by means of continuous integration of the lower-level visuo-proprioceptive stream.
Achieving Synergy in Cognitive Behavior of Humanoids via Deep Learning of Dynamic Visuo-Motor-Attentional Coordination
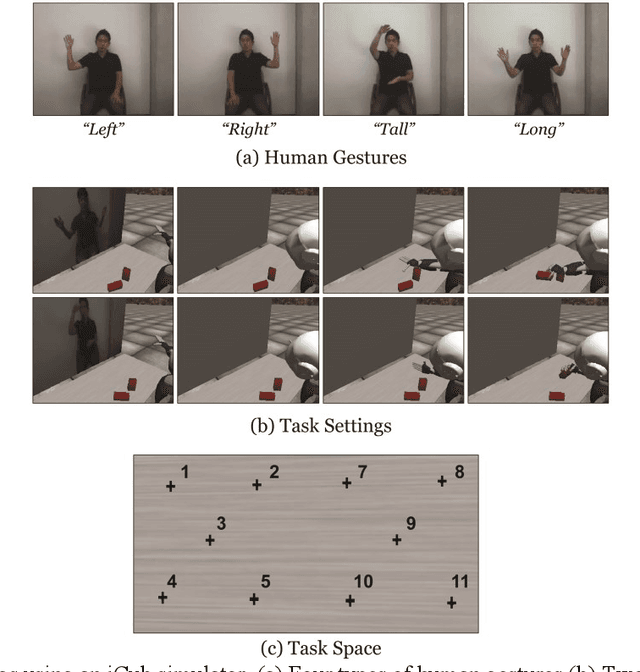
Jul 09, 2015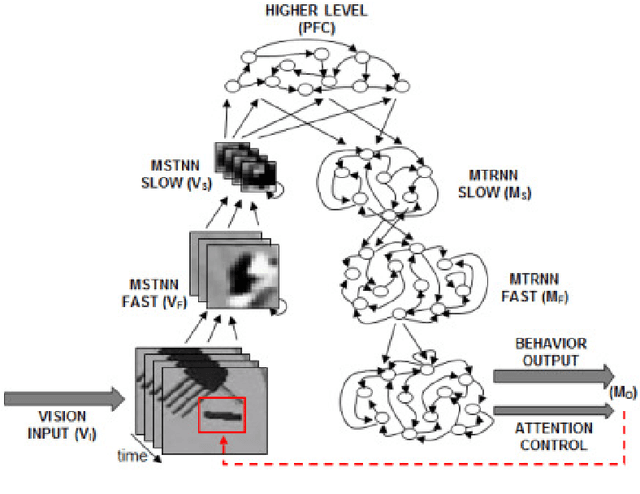
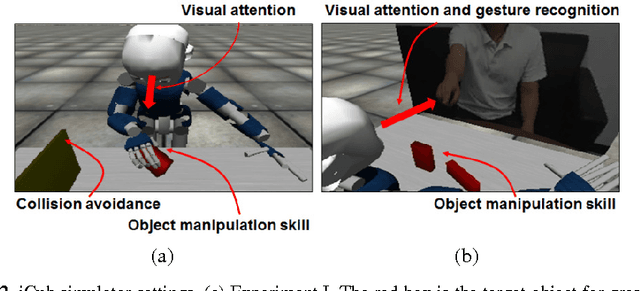

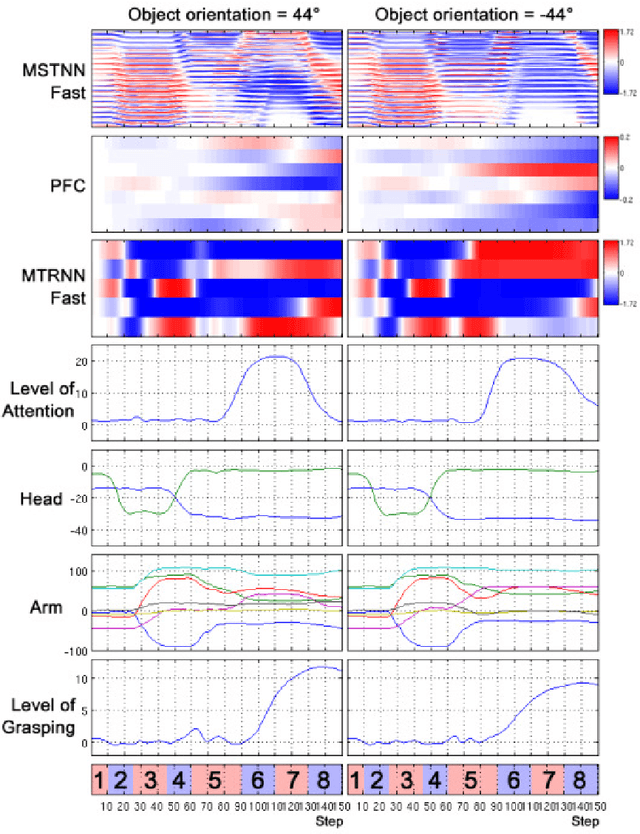
The current study examines how adequate coordination among different cognitive processes including visual recognition, attention switching, action preparation and generation can be developed via learning of robots by introducing a novel model, the Visuo-Motor Deep Dynamic Neural Network (VMDNN). The proposed model is built on coupling of a dynamic vision network, a motor generation network, and a higher level network allocated on top of these two. The simulation experiments using the iCub simulator were conducted for cognitive tasks including visual object manipulation responding to human gestures. The results showed that synergetic coordination can be developed via iterative learning through the whole network when spatio-temporal hierarchy and temporal one can be self-organized in the visual pathway and in the motor pathway, respectively, such that the higher level can manipulate them with abstraction.