 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Synergy in Cognitive Behavior of Humanoids via Deep Learning of Dynamic Visuo-Motor-Attentional Coordination
Paper and Code
Jul 09, 2015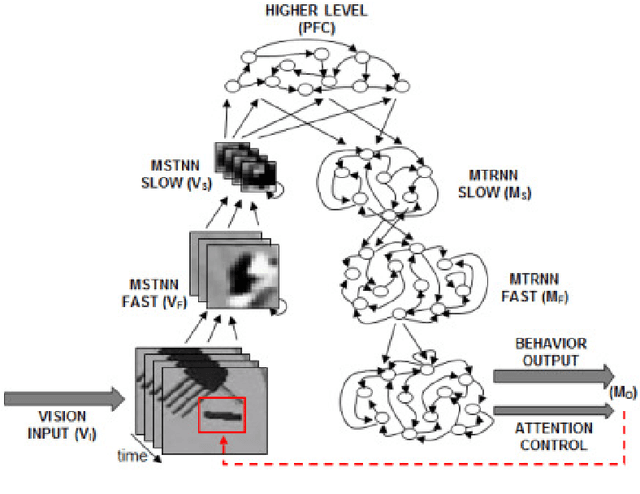
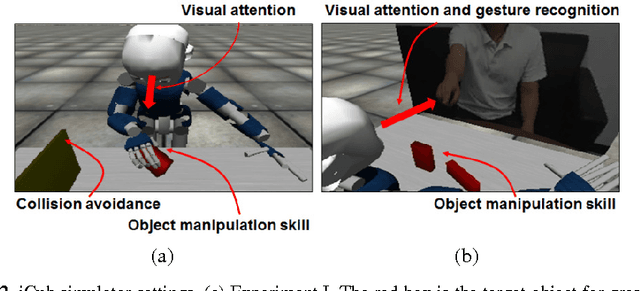

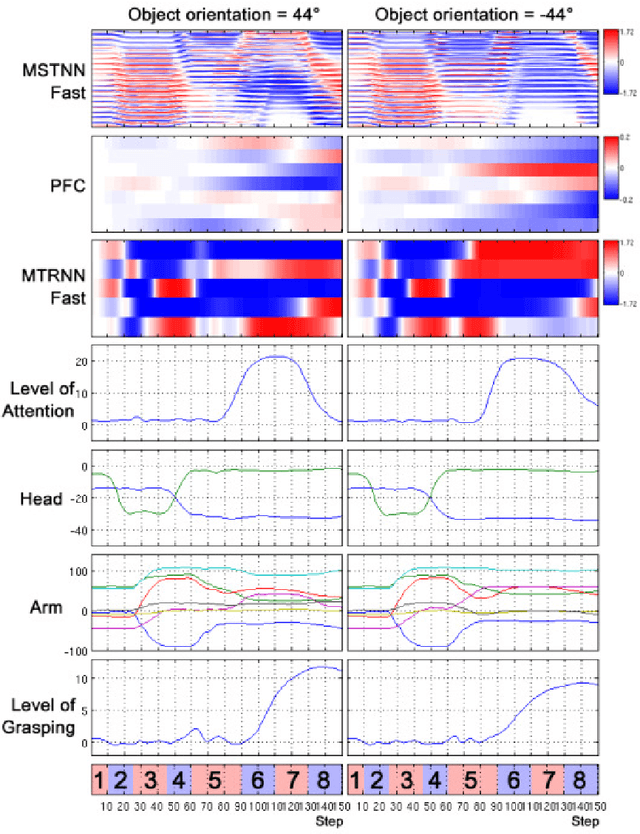
The current study examines how adequate coordination among different cognitive processes including visual recognition, attention switching, action preparation and generation can be developed via learning of robots by introducing a novel model, the Visuo-Motor Deep Dynamic Neural Network (VMDNN). The proposed model is built on coupling of a dynamic vision network, a motor generation network, and a higher level network allocated on top of these two. The simulation experiments using the iCub simulator were conducted for cognitive tasks including visual object manipulation responding to human gestures. The results showed that synergetic coordination can be developed via iterative learning through the whole network when spatio-temporal hierarchy and temporal one can be self-organized in the visual pathway and in the motor pathway, respectively, such that the higher level can manipulate them with abstraction.