 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Temporal Appearance-Geometry Network for Facial Expression Recognition
Paper and Code
Mar 05, 2015

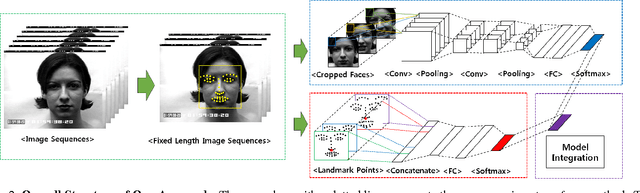

Temporal information can provide useful features for recognizing facial expressions. However, to manually design useful features requires a lot of effort. In this paper, to reduce this effort, a deep learning technique which is regarded as a tool to automatically extract useful features from raw data, is adopted. Our deep network is based on two different models. The first deep network extracts temporal geometry features from temporal facial landmark points, while the other deep network extracts temporal appearance features from image sequences . These two models are combined in order to boost the performance of the facial expression recognition. Through several experiments, we showed that the two models cooperate with each other. As a result, we achieved superior performance to other state-of-the-art methods in CK+ and Oulu-CASIA databases. Furthermore, one of the main contributions of this paper is that our deep network catches the facial action points automatically.