 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection by Effectively Leveraging Synthetic Images
Dec 29, 2025Anomaly detection plays a vital role in industrial manufacturing. Due to the scarcity of real defect images, unsupervised approaches that rely solely on normal images have been extensively studied. Recently, diffusion-based generative models brought attention to training data synthesis as an alternative solution. In this work, we focus on a strategy to effectively leverage synthetic images to maximize the anomaly detection performance. Previous synthesis strategies are broadly categorized into two groups, presenting a clear trade-off. Rule-based synthesis, such as injecting noise or pasting patches, is cost-effective but often fails to produce realistic defect images. On the other hand, generative model-based synthesis can create high-quality defect images but requires substantial cost. To address this problem, we propose a novel framework that leverages a pre-trained text-guided image-to-image translation model and image retrieval model to efficiently generate synthetic defect images. Specifically, the image retrieval model assesses the similarity of the generated images to real normal images and filters out irrelevant outputs, thereby enhancing the quality and relevance of the generated defect images. To effectively leverage synthetic images, we also introduce a two stage training strategy. In this strategy, the model is first pre-trained on a large volume of images from rule-based synthesis and then fine-tuned on a smaller set of high-quality images. This method significantly reduces the cost for data collection while improving the anomaly detection performance. Experiments on the MVTec AD dataset demonstrate the effectiveness of our approach.
SpatialMosaic: A Multiview VLM Dataset for Partial Visibility
Dec 29, 2025The rapid progress of Multimodal Large Language Models (MLLMs) has unlocked the potential for enhanced 3D scene understanding and spatial reasoning. However, existing approaches often rely on pre-constructed 3D representations or off-the-shelf reconstruction pipelines, which constrain scalability and real-world applicability. A recent line of work explores learning spatial reasoning directly from multi-view images, enabling Vision-Language Models (VLMs) to understand 3D scenes without explicit 3D reconstructions. Nevertheless, key challenges that frequently arise in real-world environments, such as partial visibility, occlusion, and low-overlap conditions that require spatial reasoning from fragmented visual cues, remain under-explored. To address these limitations, we propose a scalable multi-view data generation and annotation pipeline that constructs realistic spatial reasoning QAs, resulting in SpatialMosaic, a comprehensive instruction-tuning dataset featuring 2M QA pairs. We further introduce SpatialMosaic-Bench, a challenging benchmark for evaluating multi-view spatial reasoning under realistic and challenging scenarios, consisting of 1M QA pairs across 6 tasks. In addition, we present SpatialMosaicVLM, a hybrid framework that integrates 3D reconstruction models as geometry encoders within VLMs for robust spatial reasoning. Extensive experiments demonstrate that our proposed dataset and VQA tasks effectively enhance spatial reasoning under challenging multi-view conditions, validating the effectiveness of our data generation pipeline in constructing realistic and diverse QA pairs. Code and dataset will be available soon.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Deep Temporal Appearance-Geometry Network for Facial Expression Recognition
Mar 05, 2015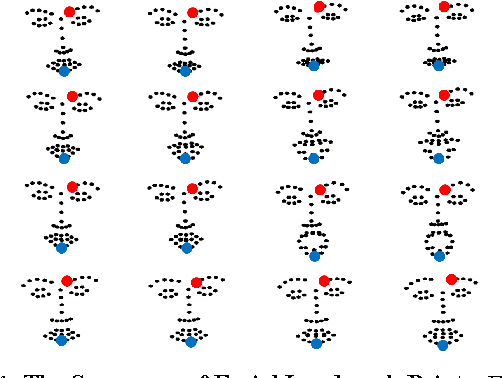

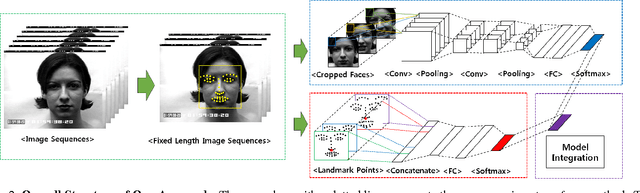

Temporal information can provide useful features for recognizing facial expressions. However, to manually design useful features requires a lot of effort. In this paper, to reduce this effort, a deep learning technique which is regarded as a tool to automatically extract useful features from raw data, is adopted. Our deep network is based on two different models. The first deep network extracts temporal geometry features from temporal facial landmark points, while the other deep network extracts temporal appearance features from image sequences . These two models are combined in order to boost the performance of the facial expression recognition. Through several experiments, we showed that the two models cooperate with each other. As a result, we achieved superior performance to other state-of-the-art methods in CK+ and Oulu-CASIA databases. Furthermore, one of the main contributions of this paper is that our deep network catches the facial action points automatically.