 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialMosaic: A Multiview VLM Dataset for Partial Visibility
Dec 29, 2025The rapid progress of Multimodal Large Language Models (MLLMs) has unlocked the potential for enhanced 3D scene understanding and spatial reasoning. However, existing approaches often rely on pre-constructed 3D representations or off-the-shelf reconstruction pipelines, which constrain scalability and real-world applicability. A recent line of work explores learning spatial reasoning directly from multi-view images, enabling Vision-Language Models (VLMs) to understand 3D scenes without explicit 3D reconstructions. Nevertheless, key challenges that frequently arise in real-world environments, such as partial visibility, occlusion, and low-overlap conditions that require spatial reasoning from fragmented visual cues, remain under-explored. To address these limitations, we propose a scalable multi-view data generation and annotation pipeline that constructs realistic spatial reasoning QAs, resulting in SpatialMosaic, a comprehensive instruction-tuning dataset featuring 2M QA pairs. We further introduce SpatialMosaic-Bench, a challenging benchmark for evaluating multi-view spatial reasoning under realistic and challenging scenarios, consisting of 1M QA pairs across 6 tasks. In addition, we present SpatialMosaicVLM, a hybrid framework that integrates 3D reconstruction models as geometry encoders within VLMs for robust spatial reasoning. Extensive experiments demonstrate that our proposed dataset and VQA tasks effectively enhance spatial reasoning under challenging multi-view conditions, validating the effectiveness of our data generation pipeline in constructing realistic and diverse QA pairs. Code and dataset will be available soon.
Instant Domain Augmentation for LiDAR Semantic Segmentation
Mar 25, 2023Despite the increasing popularity of LiDAR sensors, perception algorithms using 3D LiDAR data struggle with the 'sensor-bias problem'. Specifically, the performance of perception algorithms significantly drops when an unseen specification of LiDAR sensor is applied at test time due to the domain discrepancy. This paper presents a fast and flexible LiDAR augmentation method for the semantic segmentation task, called 'LiDomAug'. It aggregates raw LiDAR scans and creates a LiDAR scan of any configurations with the consideration of dynamic distortion and occlusion, resulting in instant domain augmentation. Our on-demand augmentation module runs at 330 FPS, so it can be seamlessly integrated into the data loader in the learning framework. In our experiments, learning-based approaches aided with the proposed LiDomAug are less affected by the sensor-bias issue and achieve new state-of-the-art domain adaptation performances on SemanticKITTI and nuScenes dataset without the use of the target domain data. We also present a sensor-agnostic model that faithfully works on the various LiDAR configurations.
Real-time Registration and Reconstruction with Cylindrical LiDAR Images
Dec 06, 2021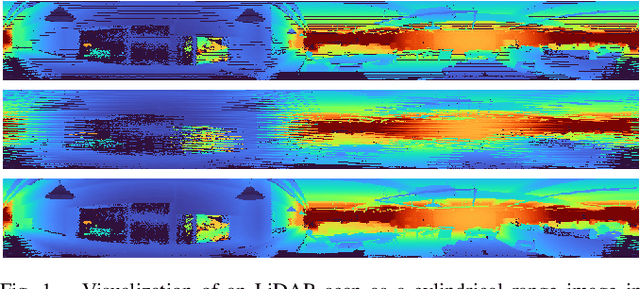

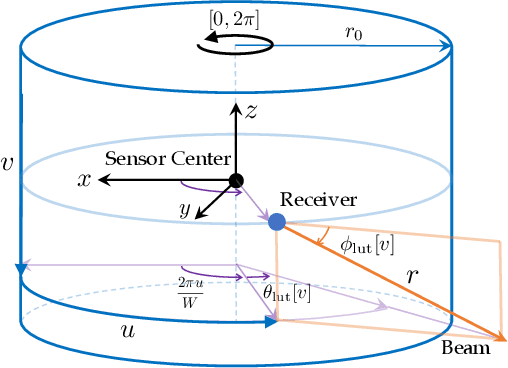

Spinning LiDAR data are prevalent for 3D perception tasks, yet its cylindrical image form is less studied. Conventional approaches regard scans as point clouds, and they either rely on expensive Euclidean 3D nearest neighbor search for data association or depend on projected range images for further processing. We revisit the LiDAR scan formation and present a cylindrical range image representation for data from raw scans, equipped with an efficient calibrated spherical projective model. With our formulation, we 1) collect a large dataset of LiDAR data consisting of both indoor and outdoor sequences accompanied with pseudo-ground truth poses; 2) evaluate the projective and conventional registration approaches on the sequences with both synthetic and real-world transformations; 3) transfer state-of-the-art RGB-D algorithms to LiDAR that runs up to 180 Hz for registration and 150 Hz for dense reconstruction. The dataset and tools will be released.