 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Adaptation for Enhancing Imitation Learning Policies
Paper and Code
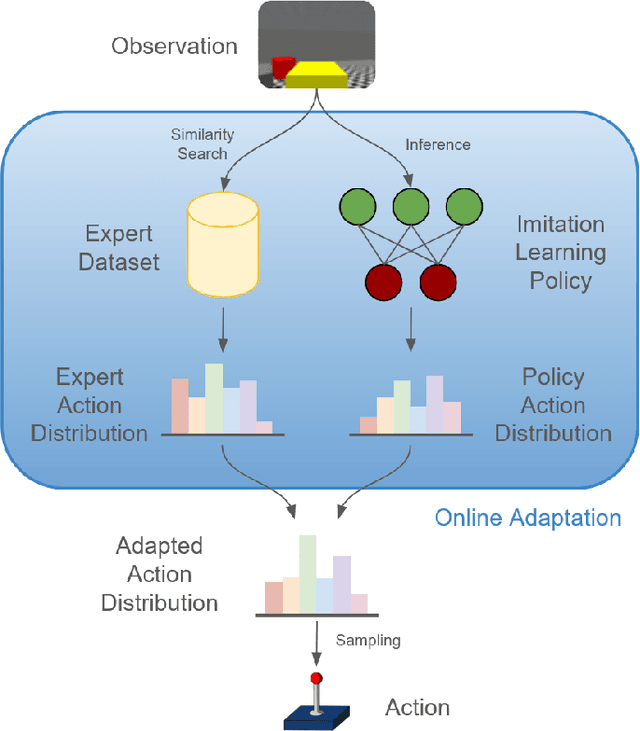

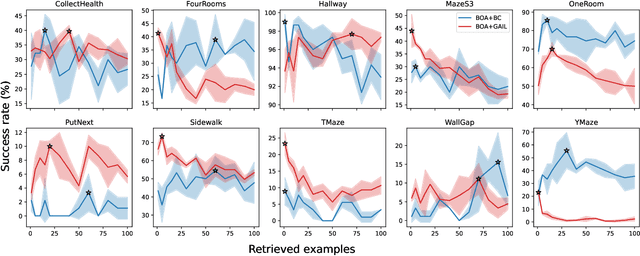
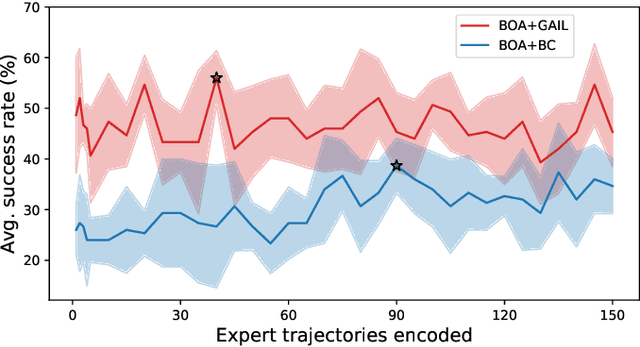
Imitation learning enables autonomous agents to learn from human examples, without the need for a reward signal. Still, if the provided dataset does not encapsulate the task correctly, or when the task is too complex to be modeled, such agents fail to reproduce the expert policy. We propose to recover from these failures through online adaptation. Our approach combines the action proposal coming from a pre-trained policy with relevant experience recorded by an expert. The combination results in an adapted action that closely follows the expert. Our experiments show that an adapted agent performs better than its pure imitation learning counterpart. Notably, adapted agents can achieve reasonable performance even when the base, non-adapted policy catastrophically fails.