 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Method for Preserving Privacy in Face Recognition System
Mar 08, 2024The state-of-the-art face recognition systems are typically trained on a single computer, utilizing extensive image datasets collected from various number of users. However, these datasets often contain sensitive personal information that users may hesitate to disclose. To address potential privacy concerns, we explore the application of federated learning, both with and without secure aggregators, in the context of both supervised and unsupervised face recognition systems. Federated learning facilitates the training of a shared model without necessitating the sharing of individual private data, achieving this by training models on decentralized edge devices housing the data. In our proposed system, each edge device independently trains its own model, which is subsequently transmitted either to a secure aggregator or directly to the central server. To introduce diverse data without the need for data transmission, we employ generative adversarial networks to generate imposter data at the edge. Following this, the secure aggregator or central server combines these individual models to construct a global model, which is then relayed back to the edge devices. Experimental findings based on the CelebA datasets reveal that employing federated learning in both supervised and unsupervised face recognition systems offers dual benefits. Firstly, it safeguards privacy since the original data remains on the edge devices. Secondly, the experimental results demonstrate that the aggregated model yields nearly identical performance compared to the individual models, particularly when the federated model does not utilize a secure aggregator. Hence, our results shed light on the practical challenges associated with privacy-preserving face image training, particularly in terms of the balance between privacy and accuracy.
Image Clustering using Restricted Boltzman Machine
Jan 15, 2024In various verification systems, Restricted Boltzmann Machines (RBMs) have demonstrated their efficacy in both front-end and back-end processes. In this work, we propose the use of RBMs to the image clustering tasks. RBMs are trained to convert images into image embeddings. We employ the conventional bottom-up Agglomerative Hierarchical Clustering (AHC) technique. To address the challenge of limited test face image data, we introduce Agglomerative Hierarchical Clustering based Method for Image Clustering using Restricted Boltzmann Machine (AHC-RBM) with two major steps. Initially, a universal RBM model is trained using all available training dataset. Subsequently, we train an adapted RBM model using the data from each test image. Finally, RBM vectors which is the embedding vector is generated by concatenating the visible-to-hidden weight matrices of these adapted models, and the bias vectors. These vectors effectively preserve class-specific information and are utilized in image clustering tasks. Our experimental results, conducted on two benchmark image datasets (MS-Celeb-1M and DeepFashion), demonstrate that our proposed approach surpasses well-known clustering algorithms such as k-means, spectral clustering, and approximate Rank-order.
Unsupervised Deep Learning Image Verification Method
Dec 22, 2023Although deep learning are commonly employed for image recognition, usually huge amount of labeled training data is required, which may not always be readily available. This leads to a noticeable performance disparity when compared to state-of-the-art unsupervised face verification techniques. In this work, we propose a method to narrow this gap by leveraging an autoencoder to convert the face image vector into a novel representation. Notably, the autoencoder is trained to reconstruct neighboring face image vectors rather than the original input image vectors. These neighbor face image vectors are chosen through an unsupervised process based on the highest cosine scores with the training face image vectors. The proposed method achieves a relative improvement of 56\% in terms of EER over the baseline system on Labeled Faces in the Wild (LFW) dataset. This has successfully narrowed down the performance gap between cosine and PLDA scoring systems.
Deep Learning Based Face Recognition Method using Siamese Network
Dec 21, 2023


Achieving state-of-the-art results in face verification systems typically hinges on the availability of labeled face training data, a resource that often proves challenging to acquire in substantial quantities. In this research endeavor, we proposed employing Siamese networks for face recognition, eliminating the need for labeled face images. We achieve this by strategically leveraging negative samples alongside nearest neighbor counterparts, thereby establishing positive and negative pairs through an unsupervised methodology. The architectural framework adopts a VGG encoder, trained as a double branch siamese network. Our primary aim is to circumvent the necessity for labeled face image data, thus proposing the generation of training pairs in an entirely unsupervised manner. Positive training data are selected within a dataset based on their highest cosine similarity scores with a designated anchor, while negative training data are culled in a parallel fashion, though drawn from an alternate dataset. During training, the proposed siamese network conducts binary classification via cross-entropy loss. Subsequently, during the testing phase, we directly extract face verification scores from the network's output layer. Experimental results reveal that the proposed unsupervised system delivers a performance on par with a similar but fully supervised baseline.
Autoencoder Based Face Verification System
Dec 21, 2023The primary objective of this work is to present an alternative approach aimed at reducing the dependency on labeled data. Our proposed method involves utilizing autoencoder pre-training within a face image recognition task with two step processes. Initially, an autoencoder is trained in an unsupervised manner using a substantial amount of unlabeled training dataset. Subsequently, a deep learning model is trained with initialized parameters from the pre-trained autoencoder. This deep learning training process is conducted in a supervised manner, employing relatively limited labeled training dataset. During evaluation phase, face image embeddings is generated as the output of deep neural network layer. Our training is executed on the CelebA dataset, while evaluation is performed using benchmark face recognition datasets such as Labeled Faces in the Wild (LFW) and YouTube Faces (YTF). Experimental results demonstrate that by initializing the deep neural network with pre-trained autoencoder parameters achieve comparable results to state-of-the-art methods.
Transferring Monolingual Model to Low-Resource Language: The Case of Tigrinya
Jun 19, 2020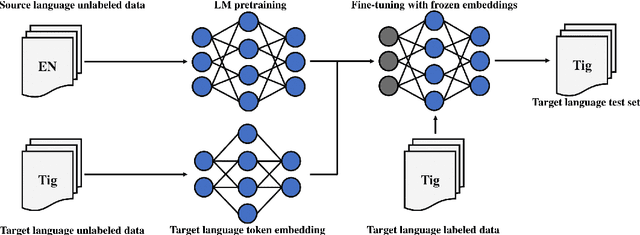


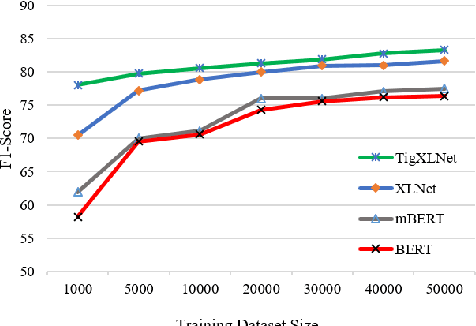
In recent years, transformer models have achieved great success in natural language processing (NLP) tasks. Most of the current state-of-the-art NLP results are achieved by using monolingual transformer models, where the model is pre-trained using a single language unlabelled text corpus. Then, the model is fine-tuned to the specific downstream task. However, the cost of pre-training a new transformer model is high for most languages. In this work, we propose a cost-effective transfer learning method to adopt a strong source language model, trained from a large monolingual corpus to a low-resource language. Thus, using XLNet language model, we demonstrate competitive performance with mBERT and a pre-trained target language model on the cross-lingual sentiment (CLS) dataset and on a new sentiment analysis dataset for low-resourced language Tigrinya. With only 10k examples of the given Tigrinya sentiment analysis dataset, English XLNet has achieved 78.88% F1-Score outperforming BERT and mBERT by 10% and 7%, respectively. More interestingly, fine-tuning (English) XLNet model on the CLS dataset has promising results compared to mBERT and even outperformed mBERT for one dataset of the Japanese language.
Do Autonomous Agents Benefit from Hearing?
May 10, 2019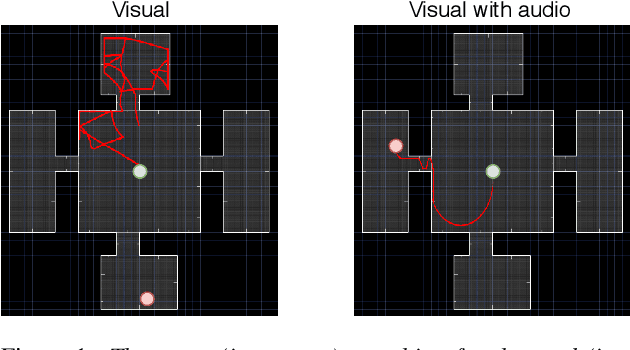

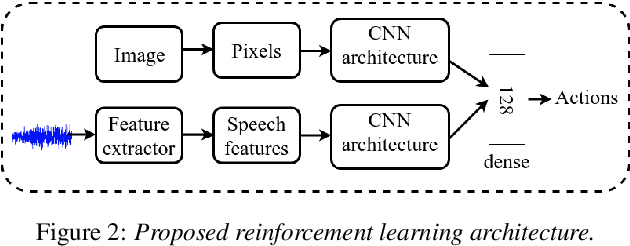
Mapping states to actions in deep reinforcement learning is mainly based on visual information. The commonly used approach for dealing with visual information is to extract pixels from images and use them as state representation for reinforcement learning agent. But, any vision only agent is handicapped by not being able to sense audible cues. Using hearing, animals are able to sense targets that are outside of their visual range. In this work, we propose the use of audio as complementary information to visual only in state representation. We assess the impact of such multi-modal setup in reach-the-goal tasks in ViZDoom environment. Results show that the agent improves its behavior when visual information is accompanied with audio features.