 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost Sensitive Optimization of Deepfake Detector
Dec 08, 2020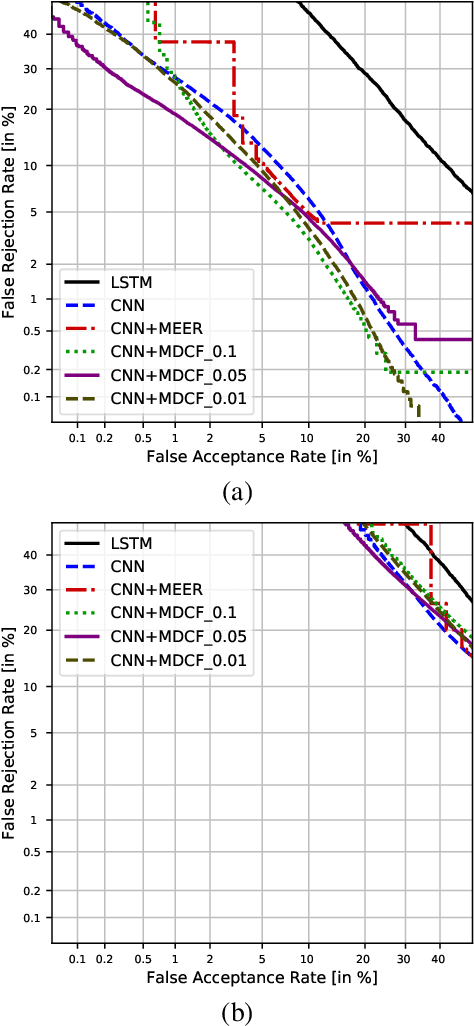
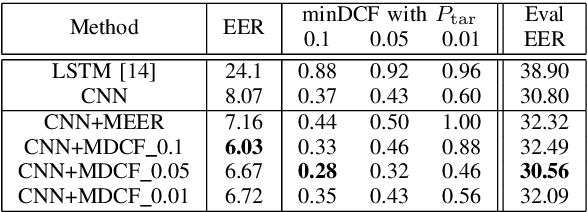
Since the invention of cinema, the manipulated videos have existed. But generating manipulated videos that can fool the viewer has been a time-consuming endeavor. With the dramatic improvements in the deep generative modeling, generating believable looking fake videos has become a reality. In the present work, we concentrate on the so-called deepfake videos, where the source face is swapped with the targets. We argue that deepfake detection task should be viewed as a screening task, where the user, such as the video streaming platform, will screen a large number of videos daily. It is clear then that only a small fraction of the uploaded videos are deepfakes, so the detection performance needs to be measured in a cost-sensitive way. Preferably, the model parameters also need to be estimated in the same way. This is precisely what we propose here.
Playing Minecraft with Behavioural Cloning
May 07, 2020
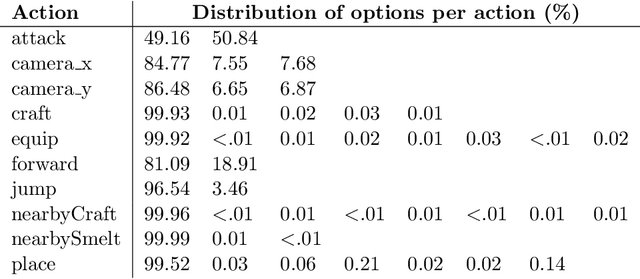


MineRL 2019 competition challenged participants to train sample-efficient agents to play Minecraft, by using a dataset of human gameplay and a limit number of steps the environment. We approached this task with behavioural cloning by predicting what actions human players would take, and reached fifth place in the final ranking. Despite being a simple algorithm, we observed the performance of such an approach can vary significantly, based on when the training is stopped. In this paper, we detail our submission to the competition, run further experiments to study how performance varied over training and study how different engineering decisions affected these results.
Do Autonomous Agents Benefit from Hearing?
May 10, 2019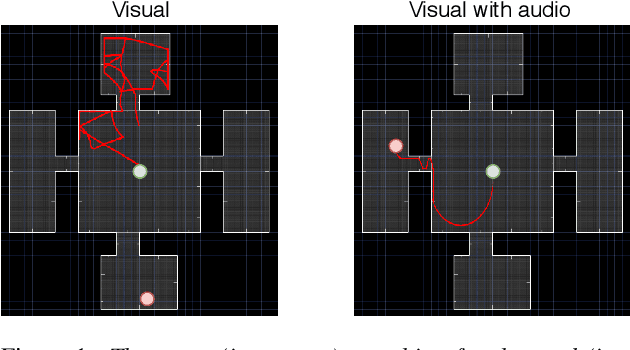

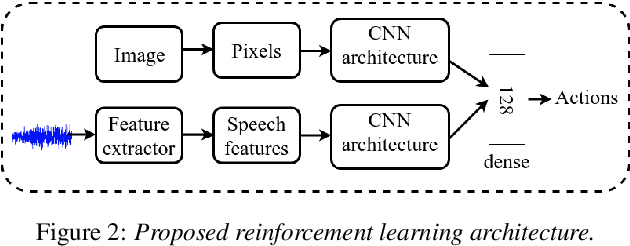
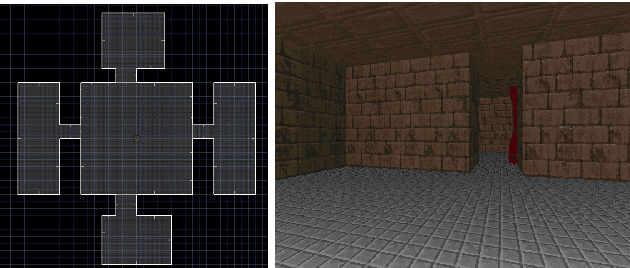
Mapping states to actions in deep reinforcement learning is mainly based on visual information. The commonly used approach for dealing with visual information is to extract pixels from images and use them as state representation for reinforcement learning agent. But, any vision only agent is handicapped by not being able to sense audible cues. Using hearing, animals are able to sense targets that are outside of their visual range. In this work, we propose the use of audio as complementary information to visual only in state representation. We assess the impact of such multi-modal setup in reach-the-goal tasks in ViZDoom environment. Results show that the agent improves its behavior when visual information is accompanied with audio features.
From Video Game to Real Robot: The Transfer between Action Spaces
May 02, 2019



Training agents with reinforcement learning based techniques requires thousands of steps, which translates to long training periods when applied to robots. By training the policy in a simulated environment we avoid such limitation. Typically, the action spaces in a simulation and real robot are kept as similar as possible, but if we want to use a generic simulation environment, this strategy will not work. Video games, such as Doom (1993), offer a crude but multi-purpose environments that can used for learning various tasks. However, original Doom has four discrete actions for movement and the robot in our case has two continuous actions. In this work, we study the transfer between these two different action spaces. We begin with experiments in a simulated environment, after which we validate the results with experiments on a real robot. Results show that fine-tuning initially learned network parameters leads to unreliable results, but by keeping most of the neural network frozen we obtain above $90\%$ success rate in simulation and real robot experiments.