 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speaker Embedding Learning with Multi-Level Pooling for Text-Independent Speaker Verification
Paper and Code
Feb 21, 2019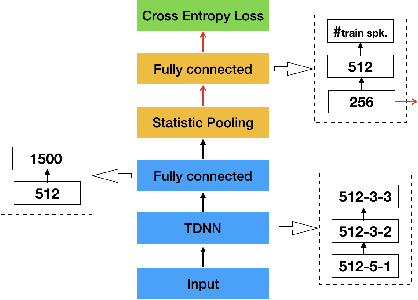

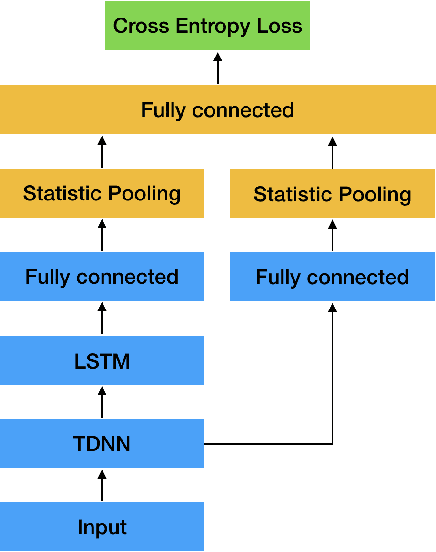
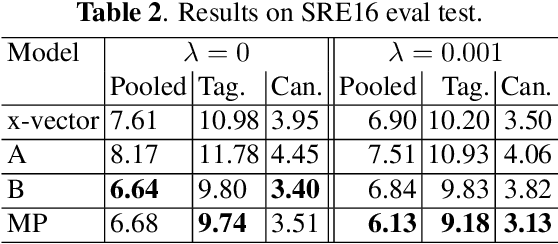
This paper aims to improve the widely used deep speaker embedding x-vector model. We propose the following improvements: (1) a hybrid neural network structure using both time delay neural network (TDNN) and long short-term memory neural networks (LSTM) to generate complementary speaker information at different levels; (2) a multi-level pooling strategy to collect speaker information from both TDNN and LSTM layers; (3) a regularization scheme on the speaker embedding extraction layer to make the extracted embeddings suitable for the following fusion step. The synergy of these improvements are shown on the NIST SRE 2016 eval test (with a 19% EER reduction) and SRE 2018 dev test (with a 9% EER reduction), as well as more than 10% DCF scores reduction on these two test sets over the x-vector baseline.