 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Is Believing: Revisiting Language Bottleneck Models for Image Classification
Jun 22, 2024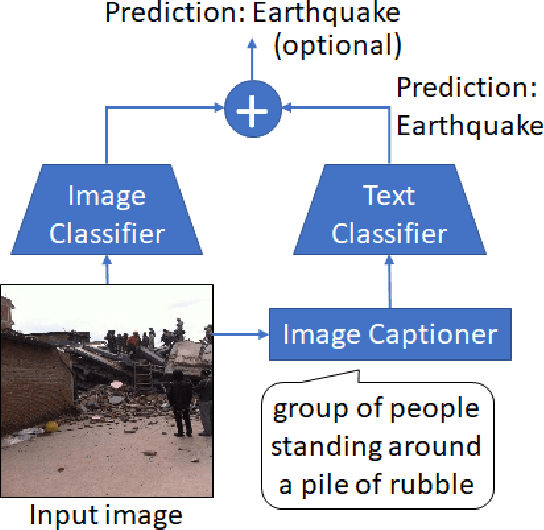
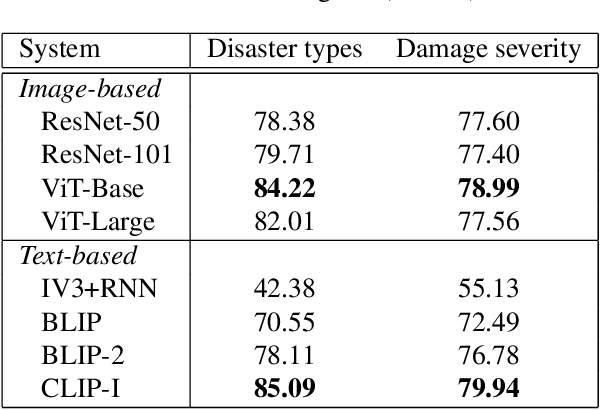

We revisit language bottleneck models as an approach to ensuring the explainability of deep learning models for image classification. Because of inevitable information loss incurred in the step of converting images into language, the accuracy of language bottleneck models is considered to be inferior to that of standard black-box models. Recent image captioners based on large-scale foundation models of Vision and Language, however, have the ability to accurately describe images in verbal detail to a degree that was previously believed to not be realistically possible. In a task of disaster image classification, we experimentally show that a language bottleneck model that combines a modern image captioner with a pre-trained language model can achieve image classification accuracy that exceeds that of black-box models. We also demonstrate that a language bottleneck model and a black-box model may be thought to extract different features from images and that fusing the two can create a synergistic effect, resulting in even higher classification accuracy.
Image Captioners Sometimes Tell More Than Images They See
May 11, 2023



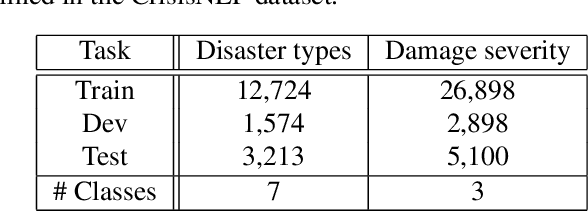
Image captioning, a.k.a. "image-to-text," which generates descriptive text from given images, has been rapidly developing throughout the era of deep learning. To what extent is the information in the original image preserved in the descriptive text generated by an image captioner? To answer that question, we have performed experiments involving the classification of images from descriptive text alone, without referring to the images at all, and compared results with those from standard image-based classifiers. We have evaluate several image captioning models with respect to a disaster image classification task, CrisisNLP, and show that descriptive text classifiers can sometimes achieve higher accuracy than standard image-based classifiers. Further, we show that fusing an image-based classifier with a descriptive text classifier can provide improvement in accuracy.