 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXi-Vector Embedding for Speaker Recognition
Paper and Code
Aug 12, 2021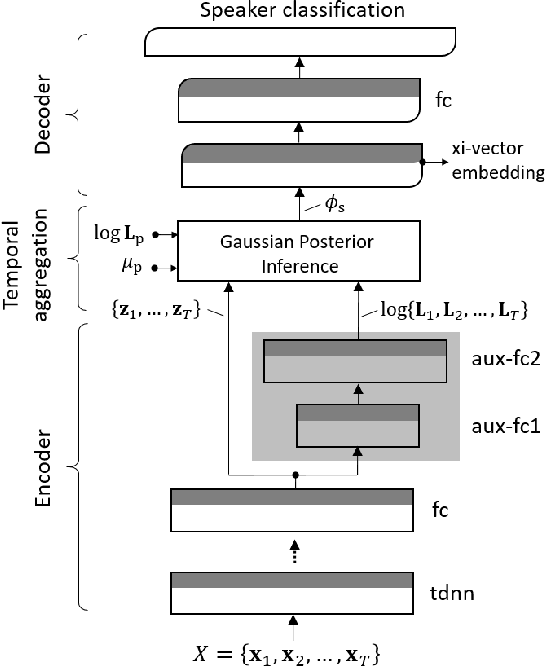

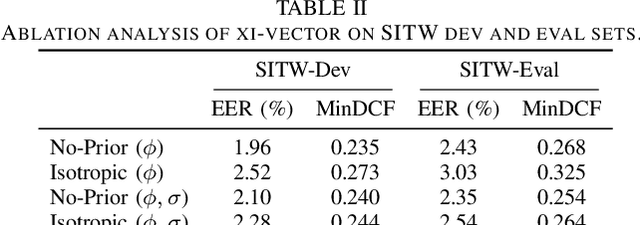

We present a Bayesian formulation for deep speaker embedding, wherein the xi-vector is the Bayesian counterpart of the x-vector, taking into account the uncertainty estimate. On the technology front, we offer a simple and straightforward extension to the now widely used x-vector. It consists of an auxiliary neural net predicting the frame-wise uncertainty of the input sequence. We show that the proposed extension leads to substantial improvement across all operating points, with a significant reduction in error rates and detection cost. On the theoretical front, our proposal integrates the Bayesian formulation of linear Gaussian model to speaker-embedding neural networks via the pooling layer. In one sense, our proposal integrates the Bayesian formulation of the i-vector to that of the x-vector. Hence, we refer to the embedding as the xi-vector, which is pronounced as /zai/ vector. Experimental results on the SITW evaluation set show a consistent improvement of over 17.5% in equal-error-rate and 10.9% in minimum detection cost.