 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning for Selecting Top-m Context-Dependent Designs
Paper and Code
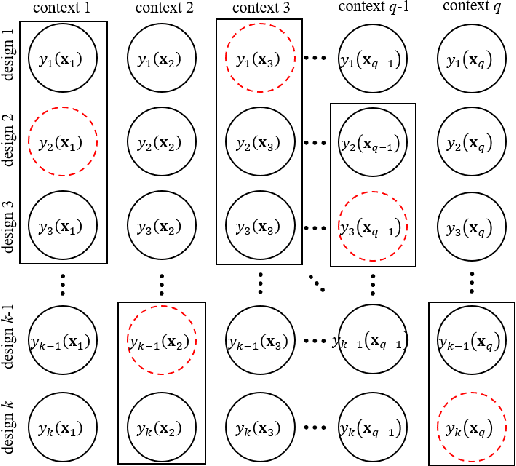
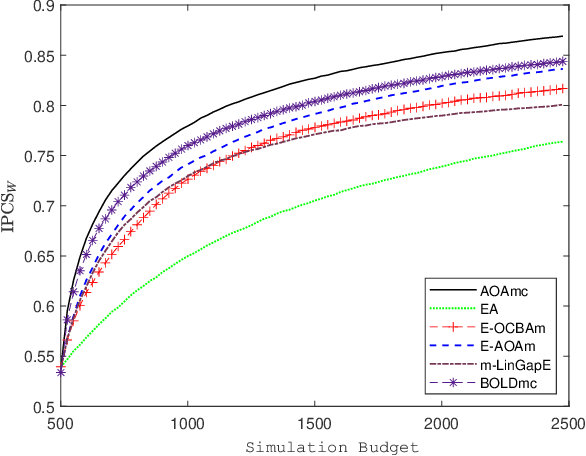
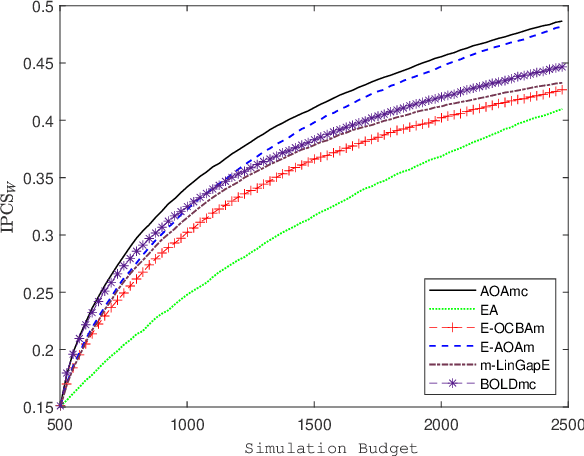

We consider a simulation optimization problem for a context-dependent decision-making, which aims to determine the top-m designs for all contexts. Under a Bayesian framework, we formulate the optimal dynamic sampling decision as a stochastic dynamic programming problem, and develop a sequential sampling policy to efficiently learn the performance of each design under each context. The asymptotically optimal sampling ratios are derived to attain the optimal large deviations rate of the worst-case of probability of false selection. The proposed sampling policy is proved to be consistent and its asymptotic sampling ratios are asymptotically optimal. Numerical experiments demonstrate that the proposed method improves the efficiency for selection of top-m context-dependent designs.