 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
Paper and Code

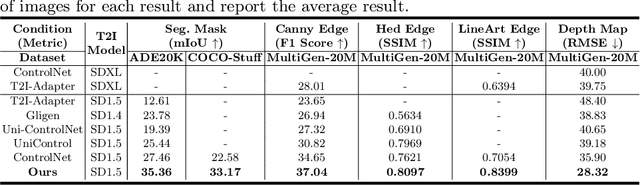
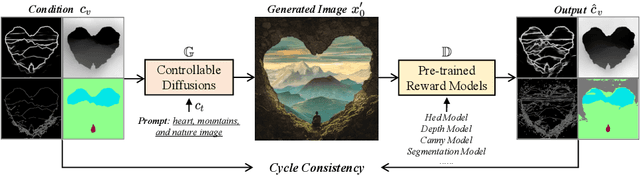
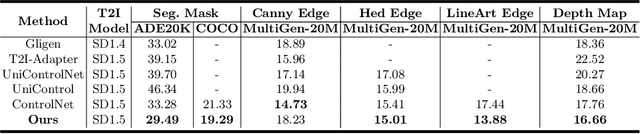
To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs. To address this, we introduce an efficient reward strategy that deliberately disturbs the input images by adding noise, and then uses the single-step denoised images for reward fine-tuning. This avoids the extensive costs associated with image sampling, allowing for more efficient reward fine-tuning. Extensive experiments show that ControlNet++ significantly improves controllability under various conditional controls. For example, it achieves improvements over ControlNet by 7.9% mIoU, 13.4% SSIM, and 7.6% RMSE, respectively, for segmentation mask, line-art edge, and depth conditions.