 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human-Object Interaction Detection via Virtual Image Learning
Paper and Code
Aug 04, 2023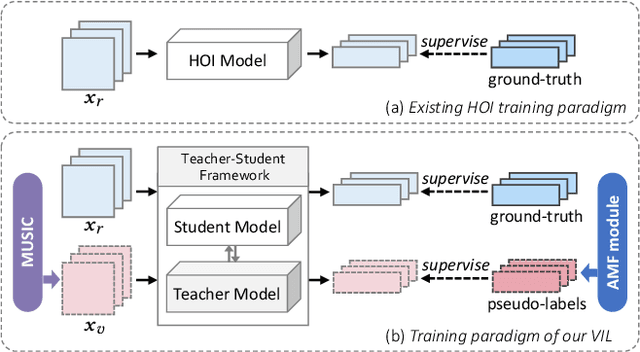
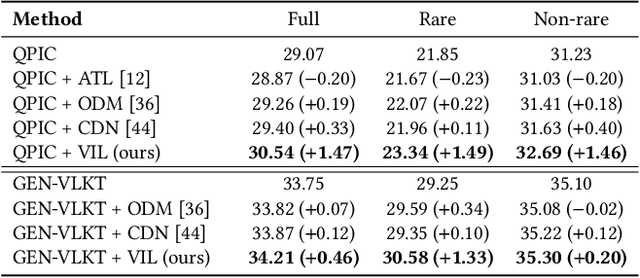
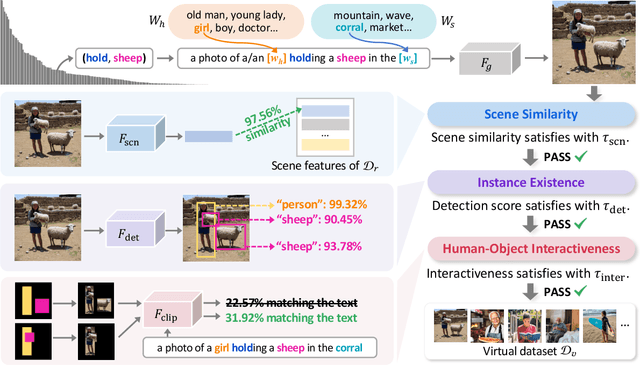
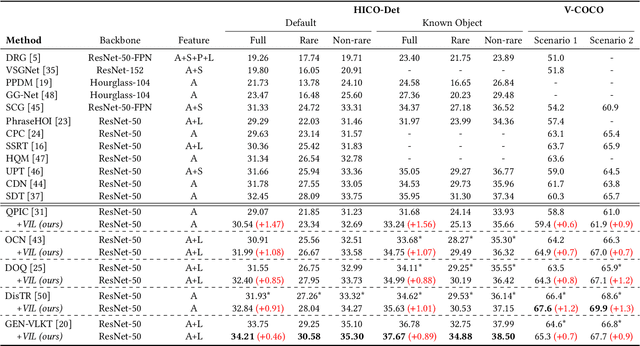
Human-Object Interaction (HOI) detection aims to understand the interactions between humans and objects, which plays a curtail role in high-level semantic understanding tasks. However, most works pursue designing better architectures to learn overall features more efficiently, while ignoring the long-tail nature of interaction-object pair categories. In this paper, we propose to alleviate the impact of such an unbalanced distribution via Virtual Image Leaning (VIL). Firstly, a novel label-to-image approach, Multiple Steps Image Creation (MUSIC), is proposed to create a high-quality dataset that has a consistent distribution with real images. In this stage, virtual images are generated based on prompts with specific characterizations and selected by multi-filtering processes. Secondly, we use both virtual and real images to train the model with the teacher-student framework. Considering the initial labels of some virtual images are inaccurate and inadequate, we devise an Adaptive Matching-and-Filtering (AMF) module to construct pseudo-labels. Our method is independent of the internal structure of HOI detectors, so it can be combined with off-the-shelf methods by training merely 10 additional epochs. With the assistance of our method, multiple methods obtain significant improvements, and new state-of-the-art results are achieved on two benchmarks.