 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHODN: Disentangling Human-Object Feature for HOI Detection
Aug 20, 2023
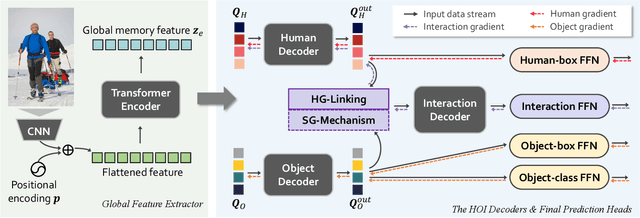
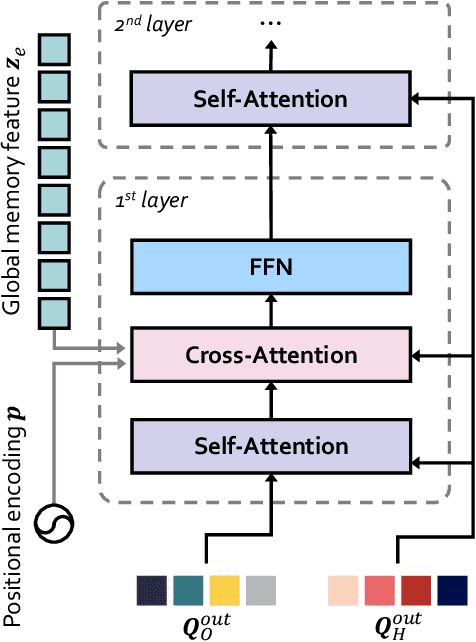
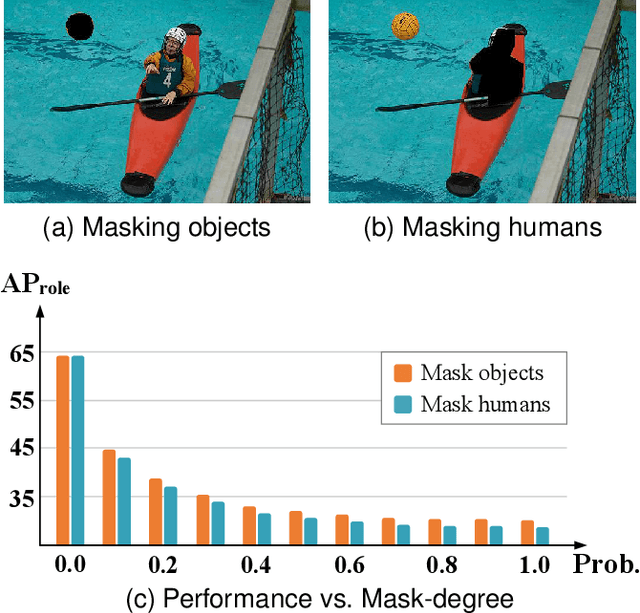
The task of Human-Object Interaction (HOI) detection is to detect humans and their interactions with surrounding objects, where transformer-based methods show dominant advances currently. However, these methods ignore the relationship among humans, objects, and interactions: 1) human features are more contributive than object ones to interaction prediction; 2) interactive information disturbs the detection of objects but helps human detection. In this paper, we propose a Human and Object Disentangling Network (HODN) to model the HOI relationships explicitly, where humans and objects are first detected by two disentangling decoders independently and then processed by an interaction decoder. Considering that human features are more contributive to interaction, we propose a Human-Guide Linking method to make sure the interaction decoder focuses on the human-centric regions with human features as the positional embeddings. To handle the opposite influences of interactions on humans and objects, we propose a Stop-Gradient Mechanism to stop interaction gradients from optimizing the object detection but to allow them to optimize the human detection. Our proposed method achieves competitive performance on both the V-COCO and the HICO-Det datasets. It can be combined with existing methods easily for state-of-the-art results.
Improving Human-Object Interaction Detection via Virtual Image Learning
Aug 04, 2023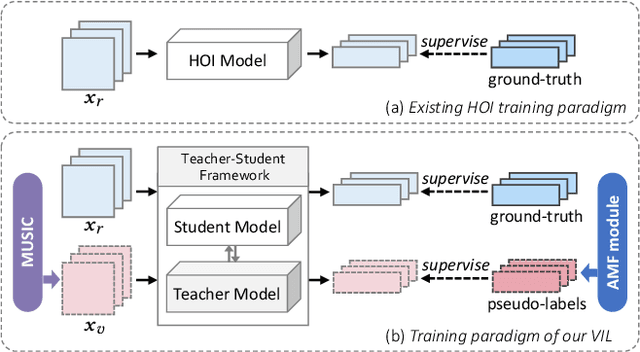
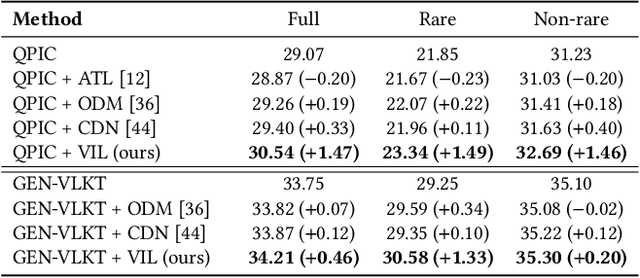
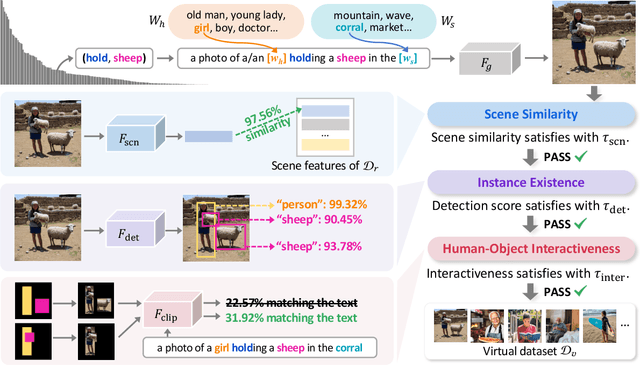
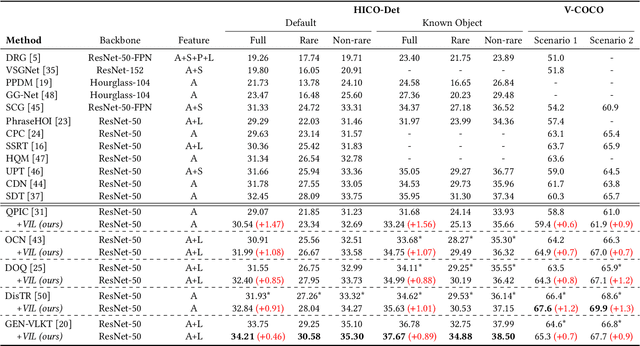
Human-Object Interaction (HOI) detection aims to understand the interactions between humans and objects, which plays a curtail role in high-level semantic understanding tasks. However, most works pursue designing better architectures to learn overall features more efficiently, while ignoring the long-tail nature of interaction-object pair categories. In this paper, we propose to alleviate the impact of such an unbalanced distribution via Virtual Image Leaning (VIL). Firstly, a novel label-to-image approach, Multiple Steps Image Creation (MUSIC), is proposed to create a high-quality dataset that has a consistent distribution with real images. In this stage, virtual images are generated based on prompts with specific characterizations and selected by multi-filtering processes. Secondly, we use both virtual and real images to train the model with the teacher-student framework. Considering the initial labels of some virtual images are inaccurate and inadequate, we devise an Adaptive Matching-and-Filtering (AMF) module to construct pseudo-labels. Our method is independent of the internal structure of HOI detectors, so it can be combined with off-the-shelf methods by training merely 10 additional epochs. With the assistance of our method, multiple methods obtain significant improvements, and new state-of-the-art results are achieved on two benchmarks.
Learning to Learn Transferable Attack
Dec 10, 2021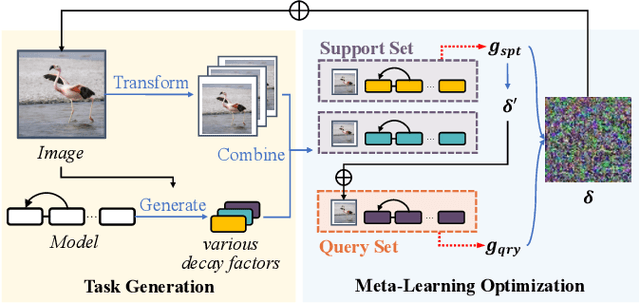
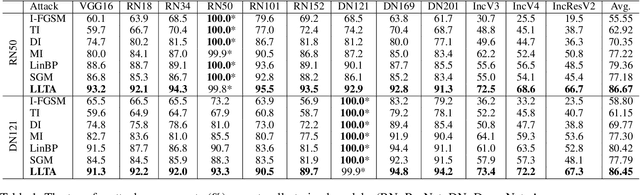
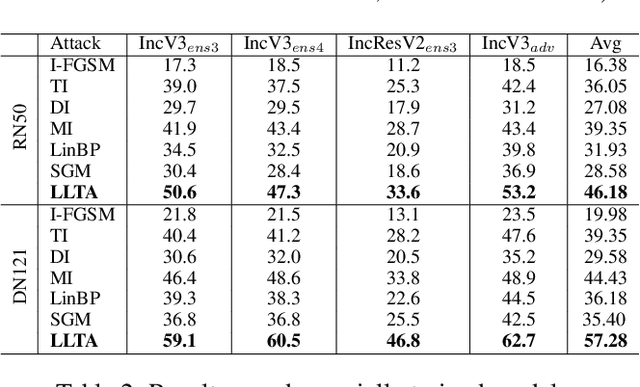
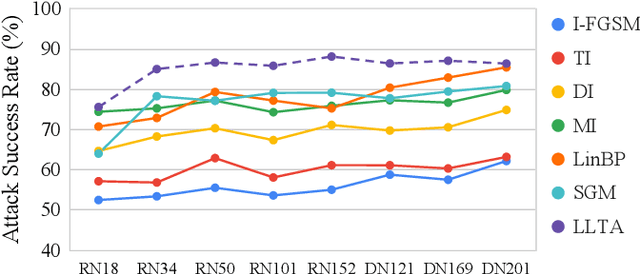
Transfer adversarial attack is a non-trivial black-box adversarial attack that aims to craft adversarial perturbations on the surrogate model and then apply such perturbations to the victim model. However, the transferability of perturbations from existing methods is still limited, since the adversarial perturbations are easily overfitting with a single surrogate model and specific data pattern. In this paper, we propose a Learning to Learn Transferable Attack (LLTA) method, which makes the adversarial perturbations more generalized via learning from both data and model augmentation. For data augmentation, we adopt simple random resizing and padding. For model augmentation, we randomly alter the back propagation instead of the forward propagation to eliminate the effect on the model prediction. By treating the attack of both specific data and a modified model as a task, we expect the adversarial perturbations to adopt enough tasks for generalization. To this end, the meta-learning algorithm is further introduced during the iteration of perturbation generation. Empirical results on the widely-used dataset demonstrate the effectiveness of our attack method with a 12.85% higher success rate of transfer attack compared with the state-of-the-art methods. We also evaluate our method on the real-world online system, i.e., Google Cloud Vision API, to further show the practical potentials of our method.