 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP: Self-supervised Pre-training for Personalized Chatbots with Multi-level Contrastive Sampling
Oct 19, 2022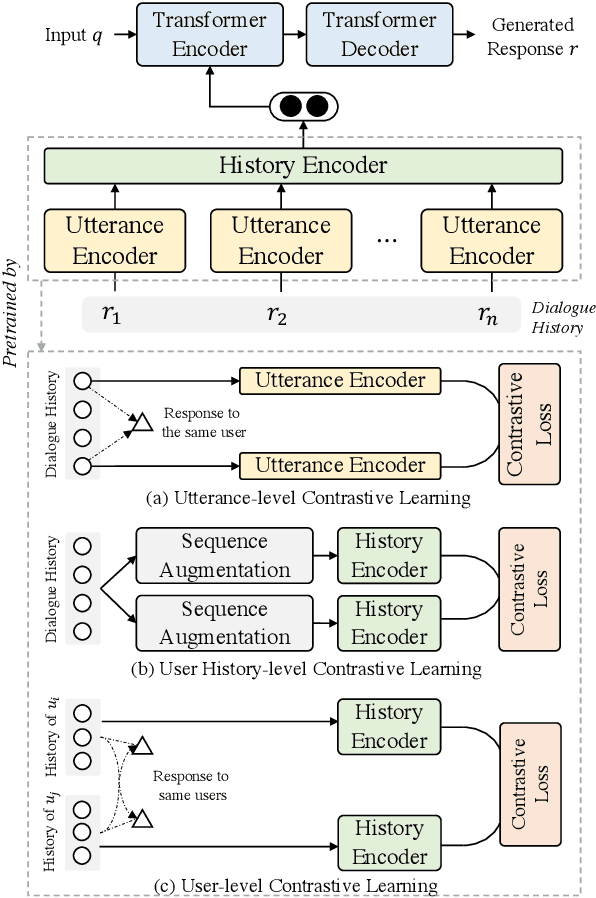
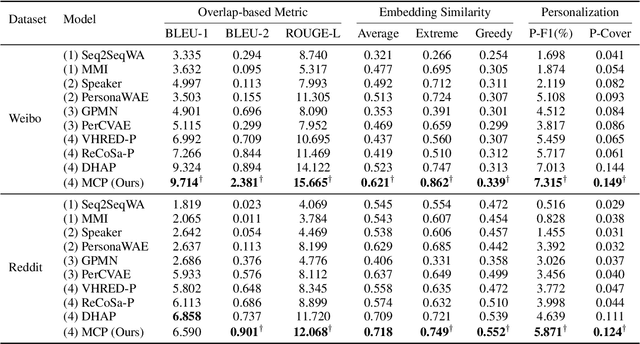
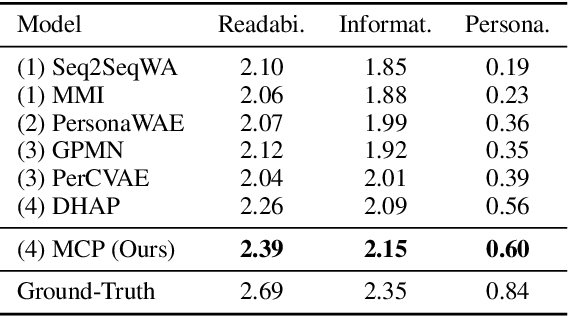
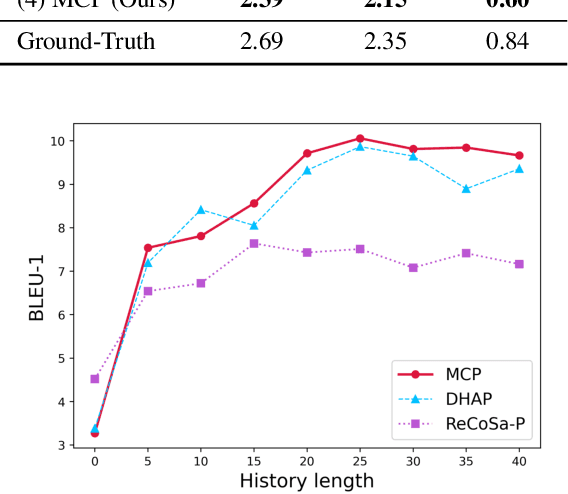
Personalized chatbots focus on endowing the chatbots with a consistent personality to behave like real users and further act as personal assistants. Previous studies have explored generating implicit user profiles from the user's dialogue history for building personalized chatbots. However, these studies only use the response generation loss to train the entire model, thus it is prone to suffer from the problem of data sparsity. Besides, they overemphasize the final generated response's quality while ignoring the correlations and fusions between the user's dialogue history, leading to rough data representations and performance degradation. To tackle these problems, we propose a self-supervised learning framework MCP for capturing better representations from users' dialogue history for personalized chatbots. Specifically, we apply contrastive sampling methods to leverage the supervised signals hidden in user dialog history, and generate the pre-training samples for enhancing the model. We design three pre-training tasks based on three types of contrastive pairs from user dialogue history, namely response pairs, sequence augmentation pairs, and user pairs. We pre-train the utterance encoder and the history encoder towards the contrastive objectives and use these pre-trained encoders for generating user profiles while personalized response generation. Experimental results on two real-world datasets show a significant improvement in our proposed model MCP compared with the existing methods.
Socialformer: Social Network Inspired Long Document Modeling for Document Ranking
Feb 22, 2022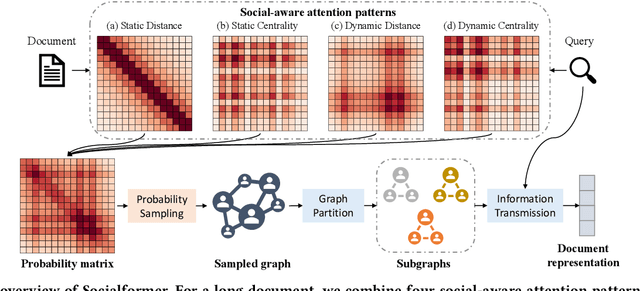
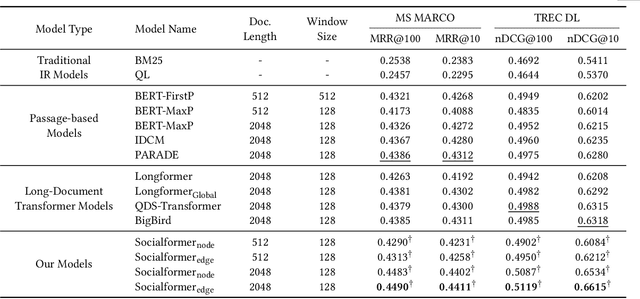
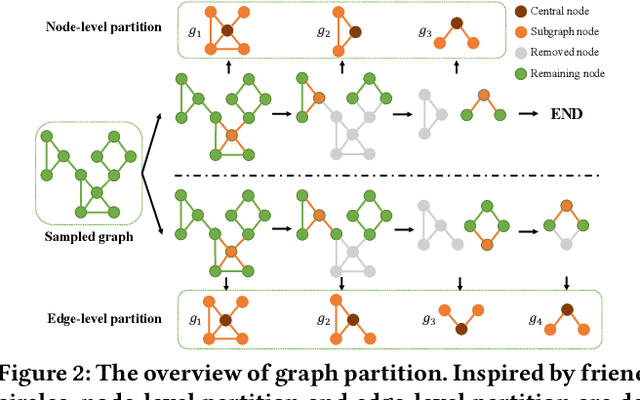

Utilizing pre-trained language models has achieved great success for neural document ranking. Limited by the computational and memory requirements, long document modeling becomes a critical issue. Recent works propose to modify the full attention matrix in Transformer by designing sparse attention patterns. However, most of them only focus on local connections of terms within a fixed-size window. How to build suitable remote connections between terms to better model document representation remains underexplored. In this paper, we propose the model Socialformer, which introduces the characteristics of social networks into designing sparse attention patterns for long document modeling in document ranking. Specifically, we consider several attention patterns to construct a graph like social networks. Endowed with the characteristic of social networks, most pairs of nodes in such a graph can reach with a short path while ensuring the sparsity. To facilitate efficient calculation, we segment the graph into multiple subgraphs to simulate friend circles in social scenarios. Experimental results confirm the effectiveness of our model on long document modeling.
One Chatbot Per Person: Creating Personalized Chatbots based on Implicit User Profiles
Sep 02, 2021
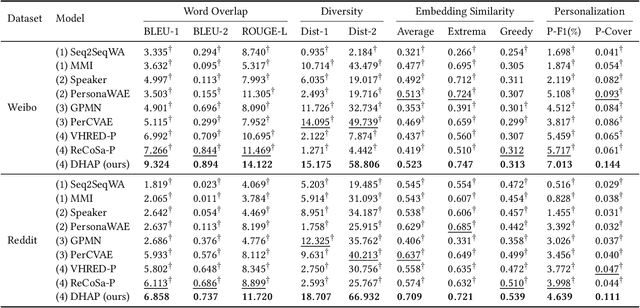
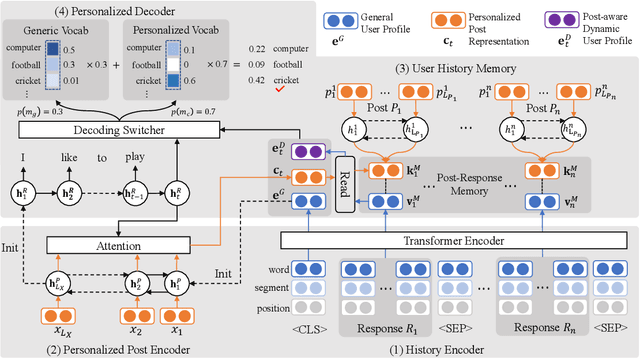
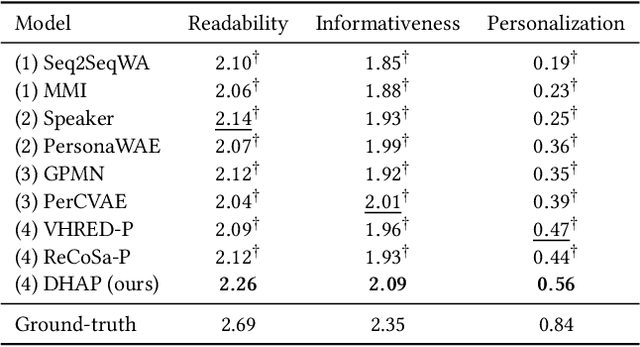
Personalized chatbots focus on endowing chatbots with a consistent personality to behave like real users, give more informative responses, and further act as personal assistants. Existing personalized approaches tried to incorporate several text descriptions as explicit user profiles. However, the acquisition of such explicit profiles is expensive and time-consuming, thus being impractical for large-scale real-world applications. Moreover, the restricted predefined profile neglects the language behavior of a real user and cannot be automatically updated together with the change of user interests. In this paper, we propose to learn implicit user profiles automatically from large-scale user dialogue history for building personalized chatbots. Specifically, leveraging the benefits of Transformer on language understanding, we train a personalized language model to construct a general user profile from the user's historical responses. To highlight the relevant historical responses to the input post, we further establish a key-value memory network of historical post-response pairs, and build a dynamic post-aware user profile. The dynamic profile mainly describes what and how the user has responded to similar posts in history. To explicitly utilize users' frequently used words, we design a personalized decoder to fuse two decoding strategies, including generating a word from the generic vocabulary and copying one word from the user's personalized vocabulary. Experiments on two real-world datasets show the significant improvement of our model compared with existing methods. Our code is available at https://github.com/zhengyima/DHAP
Contrastive Learning of User Behavior Sequence for Context-Aware Document Ranking
Aug 24, 2021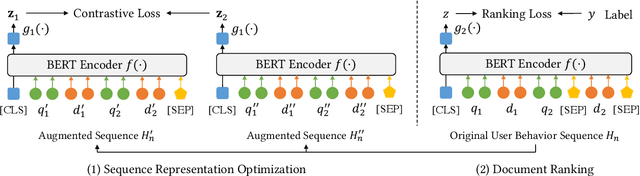
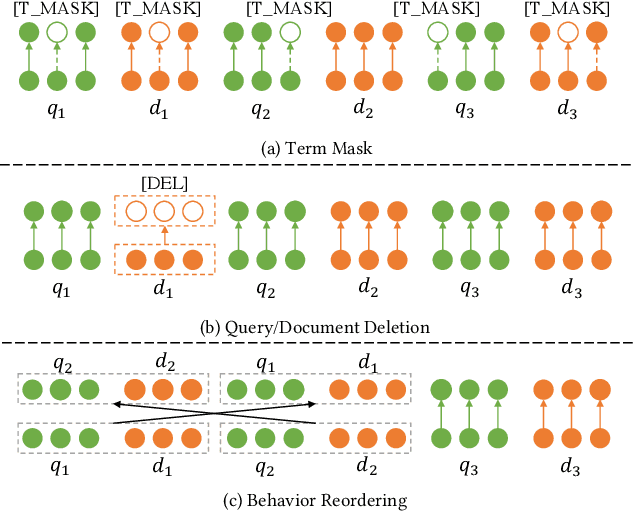
Context information in search sessions has proven to be useful for capturing user search intent. Existing studies explored user behavior sequences in sessions in different ways to enhance query suggestion or document ranking. However, a user behavior sequence has often been viewed as a definite and exact signal reflecting a user's behavior. In reality, it is highly variable: user's queries for the same intent can vary, and different documents can be clicked. To learn a more robust representation of the user behavior sequence, we propose a method based on contrastive learning, which takes into account the possible variations in user's behavior sequences. Specifically, we propose three data augmentation strategies to generate similar variants of user behavior sequences and contrast them with other sequences. In so doing, the model is forced to be more robust regarding the possible variations. The optimized sequence representation is incorporated into document ranking. Experiments on two real query log datasets show that our proposed model outperforms the state-of-the-art methods significantly, which demonstrates the effectiveness of our method for context-aware document ranking.
Pre-training for Ad-hoc Retrieval: Hyperlink is Also You Need
Aug 20, 2021
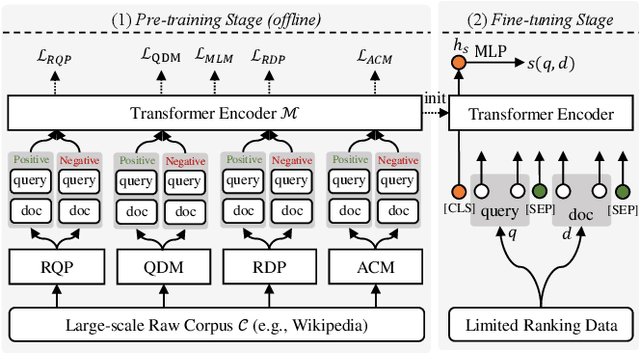
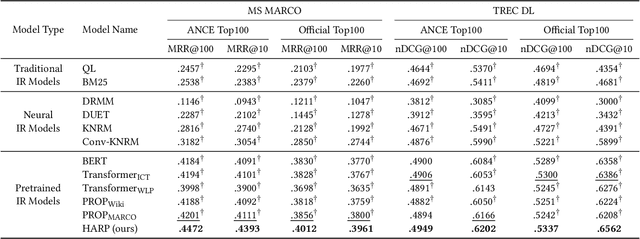
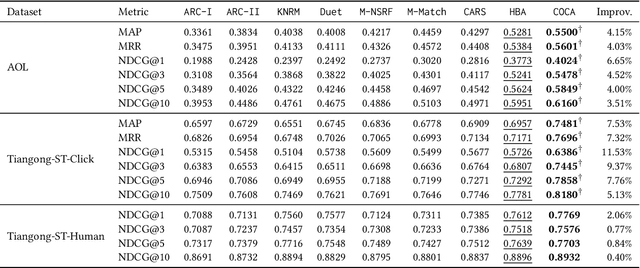
Designing pre-training objectives that more closely resemble the downstream tasks for pre-trained language models can lead to better performance at the fine-tuning stage, especially in the ad-hoc retrieval area. Existing pre-training approaches tailored for IR tried to incorporate weak supervised signals, such as query-likelihood based sampling, to construct pseudo query-document pairs from the raw textual corpus. However, these signals rely heavily on the sampling method. For example, the query likelihood model may lead to much noise in the constructed pre-training data. \blfootnote{$\dagger$ This work was done during an internship at Huawei.} In this paper, we propose to leverage the large-scale hyperlinks and anchor texts to pre-train the language model for ad-hoc retrieval. Since the anchor texts are created by webmasters and can usually summarize the target document, it can help to build more accurate and reliable pre-training samples than a specific algorithm. Considering different views of the downstream ad-hoc retrieval, we devise four pre-training tasks based on the hyperlinks. We then pre-train the Transformer model to predict the pair-wise preference, jointly with the Masked Language Model objective. Experimental results on two large-scale ad-hoc retrieval datasets show the significant improvement of our model compared with the existing methods.