 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Token Can Help! Learning Scalable and Pluggable Virtual Tokens for Retrieval-Augmented Large Language Models
May 31, 2024Retrieval-augmented generation (RAG) is a promising way to improve large language models (LLMs) for generating more factual, accurate, and up-to-date content. Existing methods either optimize prompts to guide LLMs in leveraging retrieved information or directly fine-tune the LLMs to adapt to RAG scenarios. Although fine-tuning can yield better performance, it often compromises the LLMs' general generation capabilities by modifying their parameters. This limitation poses challenges in practical applications, especially when LLMs are already deployed, as parameter adjustments may affect their original functionality. To address this, we propose a novel method that involves learning scalable and pluggable virtual tokens for RAG. By maintaining the LLMs' original parameters and fine-tuning only the embeddings of these pluggable tokens, our approach not only enhances LLMs' performance but also preserves their general generation capacities. Furthermore, we design several training strategies to improve the scalability, flexibility, and generalizability of our method. Comprehensive experiments across nine question-answering tasks demonstrate the superiority of our approach.
UFO: a Unified and Flexible Framework for Evaluating Factuality of Large Language Models
Feb 22, 2024



Large language models (LLMs) may generate text that lacks consistency with human knowledge, leading to factual inaccuracies or \textit{hallucination}. Existing research for evaluating the factuality of LLMs involves extracting fact claims using an LLM and verifying them against a predefined fact source. However, these evaluation metrics are task-specific, and not scalable, and the substitutability of fact sources in different tasks is under-explored. To address these challenges, we categorize four available fact sources: human-written evidence, reference documents, search engine results, and LLM knowledge, along with five text generation tasks containing six representative datasets. Then, we propose \texttt{UFO}, an LLM-based unified and flexible evaluation framework to verify facts against plug-and-play fact sources. We implement five evaluation scenarios based on this framework. Experimental results show that for most QA tasks, human-written evidence and reference documents are crucial, and they can substitute for each other in retrieval-augmented QA tasks. In news fact generation tasks, search engine results and LLM knowledge are essential. Our dataset and code are available at \url{https://github.com/WaldenRUC/UFO}.
MCP: Self-supervised Pre-training for Personalized Chatbots with Multi-level Contrastive Sampling
Oct 19, 2022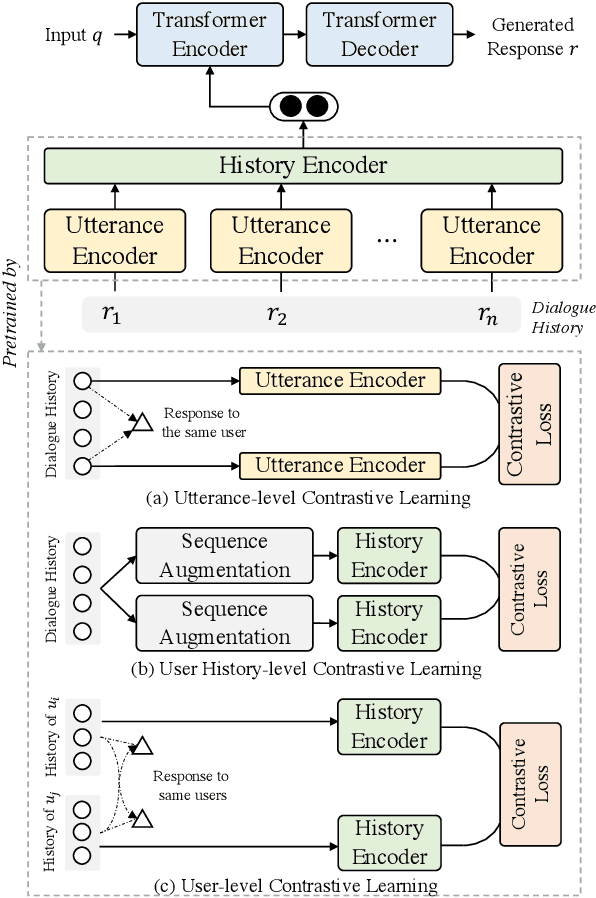
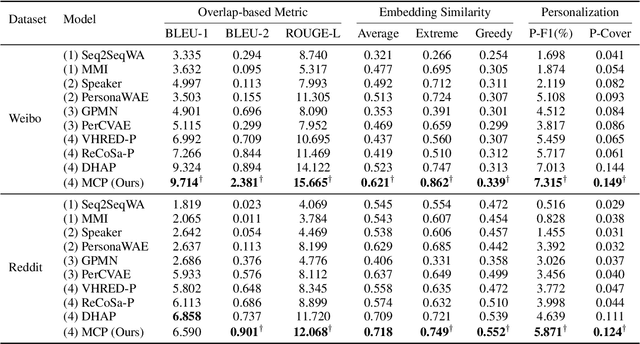
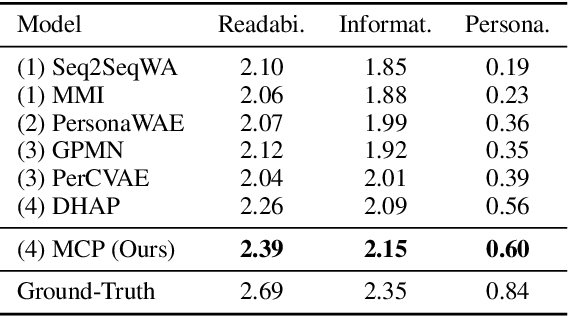
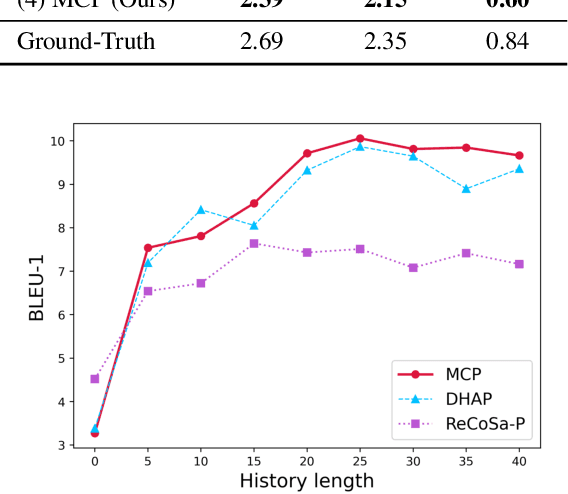
Personalized chatbots focus on endowing the chatbots with a consistent personality to behave like real users and further act as personal assistants. Previous studies have explored generating implicit user profiles from the user's dialogue history for building personalized chatbots. However, these studies only use the response generation loss to train the entire model, thus it is prone to suffer from the problem of data sparsity. Besides, they overemphasize the final generated response's quality while ignoring the correlations and fusions between the user's dialogue history, leading to rough data representations and performance degradation. To tackle these problems, we propose a self-supervised learning framework MCP for capturing better representations from users' dialogue history for personalized chatbots. Specifically, we apply contrastive sampling methods to leverage the supervised signals hidden in user dialog history, and generate the pre-training samples for enhancing the model. We design three pre-training tasks based on three types of contrastive pairs from user dialogue history, namely response pairs, sequence augmentation pairs, and user pairs. We pre-train the utterance encoder and the history encoder towards the contrastive objectives and use these pre-trained encoders for generating user profiles while personalized response generation. Experimental results on two real-world datasets show a significant improvement in our proposed model MCP compared with the existing methods.