 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM-based Recommendation with Self-Hard Negatives from Intermediate Layers
Feb 19, 2026Large language models (LLMs) have shown great promise in recommender systems, where supervised fine-tuning (SFT) is commonly used for adaptation. Subsequent studies further introduce preference learning to incorporate negative samples into the training process. However, existing methods rely on sequence-level, offline-generated negatives, making them less discriminative and informative when adapting LLMs to recommendation tasks with large negative item spaces. To address these challenges, we propose ILRec, a novel preference fine-tuning framework for LLM-based recommendation, leveraging self-hard negative signals extracted from intermediate layers to improve preference learning. Specifically, we identify self-hard negative tokens from intermediate layers as fine-grained negative supervision that dynamically reflects the model's preference learning process. To effectively integrate these signals into training, we design a two-stage framework comprising cross-layer preference optimization and cross-layer preference distillation, enabling the model to jointly discriminate informative negatives and enhance the quality of negative signals from intermediate layers. In addition, we introduce a lightweight collaborative filtering model to assign token-level rewards for negative signals, mitigating the risk of over-penalizing false negatives. Extensive experiments on three datasets demonstrate ILRec's effectiveness in enhancing the performance of LLM-based recommender systems.
UFO: a Unified and Flexible Framework for Evaluating Factuality of Large Language Models
Feb 22, 2024



Large language models (LLMs) may generate text that lacks consistency with human knowledge, leading to factual inaccuracies or \textit{hallucination}. Existing research for evaluating the factuality of LLMs involves extracting fact claims using an LLM and verifying them against a predefined fact source. However, these evaluation metrics are task-specific, and not scalable, and the substitutability of fact sources in different tasks is under-explored. To address these challenges, we categorize four available fact sources: human-written evidence, reference documents, search engine results, and LLM knowledge, along with five text generation tasks containing six representative datasets. Then, we propose \texttt{UFO}, an LLM-based unified and flexible evaluation framework to verify facts against plug-and-play fact sources. We implement five evaluation scenarios based on this framework. Experimental results show that for most QA tasks, human-written evidence and reference documents are crucial, and they can substitute for each other in retrieval-augmented QA tasks. In news fact generation tasks, search engine results and LLM knowledge are essential. Our dataset and code are available at \url{https://github.com/WaldenRUC/UFO}.
Temporal Embedding in Convolutional Neural Networks for Robust Learning of Abstract Snippets
Feb 18, 2015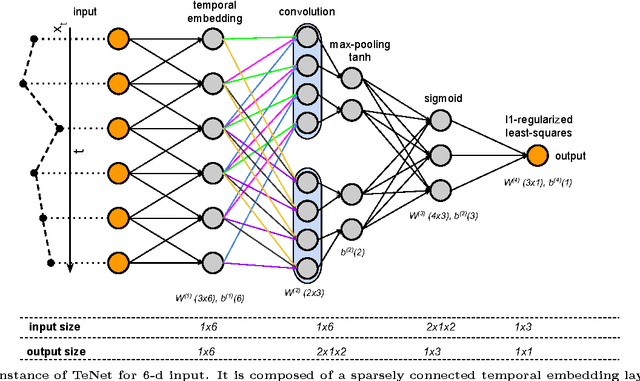
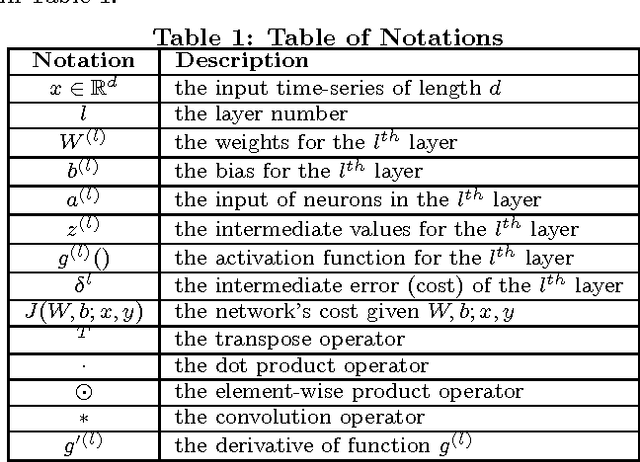
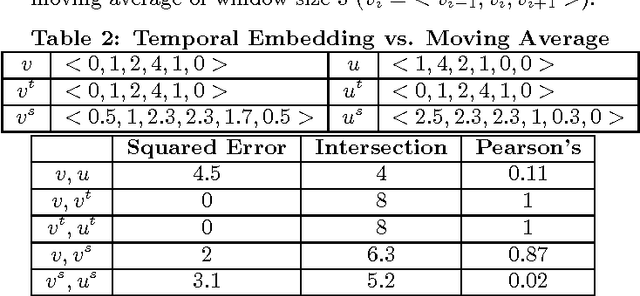
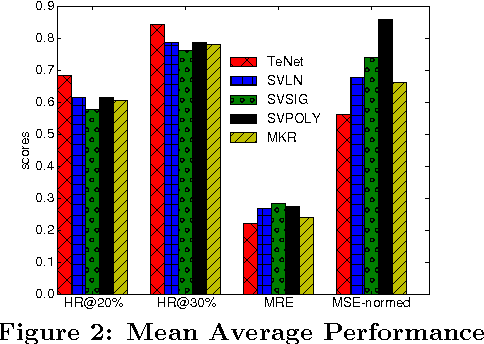
The prediction of periodical time-series remains challenging due to various types of data distortions and misalignments. Here, we propose a novel model called Temporal embedding-enhanced convolutional neural Network (TeNet) to learn repeatedly-occurring-yet-hidden structural elements in periodical time-series, called abstract snippets, for predicting future changes. Our model uses convolutional neural networks and embeds a time-series with its potential neighbors in the temporal domain for aligning it to the dominant patterns in the dataset. The model is robust to distortions and misalignments in the temporal domain and demonstrates strong prediction power for periodical time-series. We conduct extensive experiments and discover that the proposed model shows significant and consistent advantages over existing methods on a variety of data modalities ranging from human mobility to household power consumption records. Empirical results indicate that the model is robust to various factors such as number of samples, variance of data, numerical ranges of data etc. The experiments also verify that the intuition behind the model can be generalized to multiple data types and applications and promises significant improvement in prediction performances across the datasets studied.