 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Learning to Refine Dialogue History for Personalized Dialogue Generation
Apr 18, 2022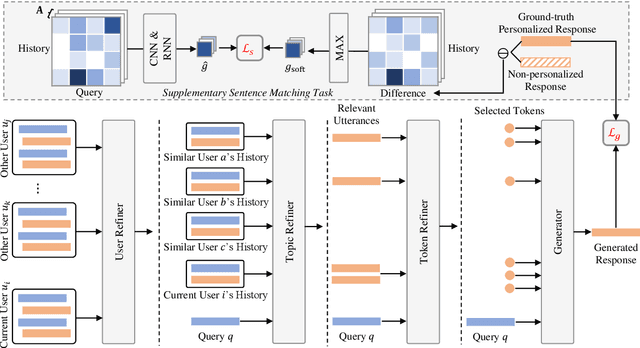
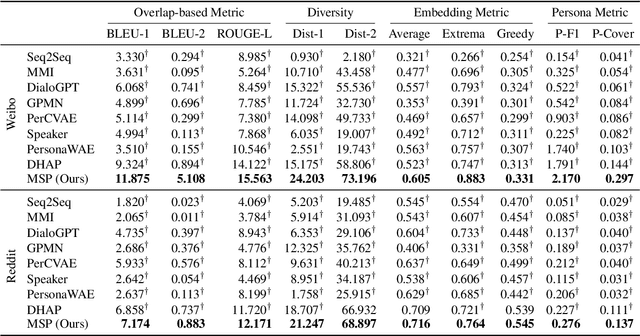
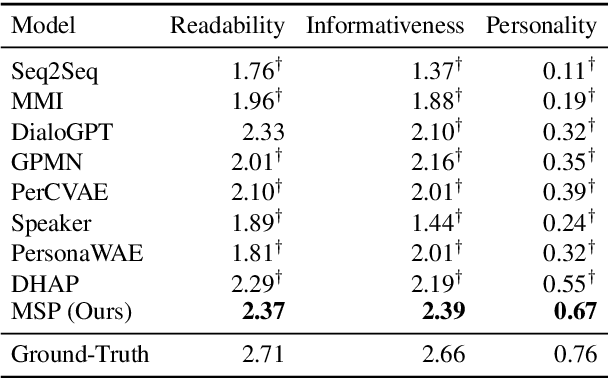
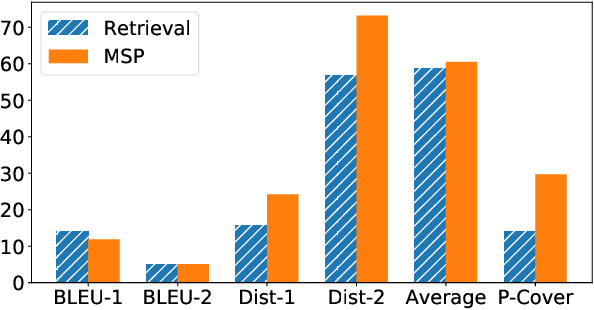
Personalized dialogue systems explore the problem of generating responses that are consistent with the user's personality, which has raised much attention in recent years. Existing personalized dialogue systems have tried to extract user profiles from dialogue history to guide personalized response generation. Since the dialogue history is usually long and noisy, most existing methods truncate the dialogue history to model the user's personality. Such methods can generate some personalized responses, but a large part of dialogue history is wasted, leading to sub-optimal performance of personalized response generation. In this work, we propose to refine the user dialogue history on a large scale, based on which we can handle more dialogue history and obtain more abundant and accurate persona information. Specifically, we design an MSP model which consists of three personal information refiners and a personalized response generator. With these multi-level refiners, we can sparsely extract the most valuable information (tokens) from the dialogue history and leverage other similar users' data to enhance personalization. Experimental results on two real-world datasets demonstrate the superiority of our model in generating more informative and personalized responses.
One Chatbot Per Person: Creating Personalized Chatbots based on Implicit User Profiles
Sep 02, 2021
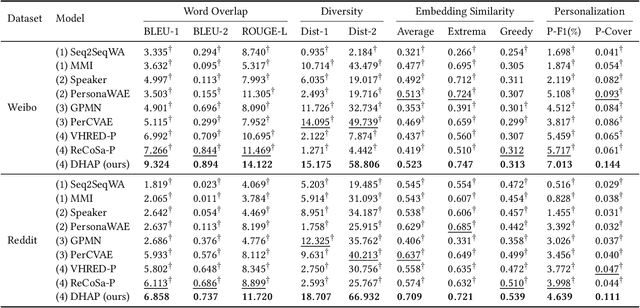
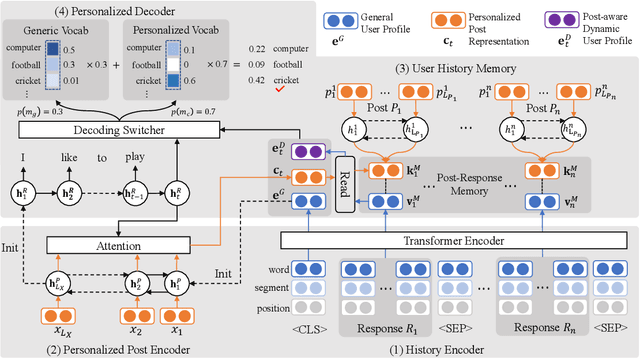
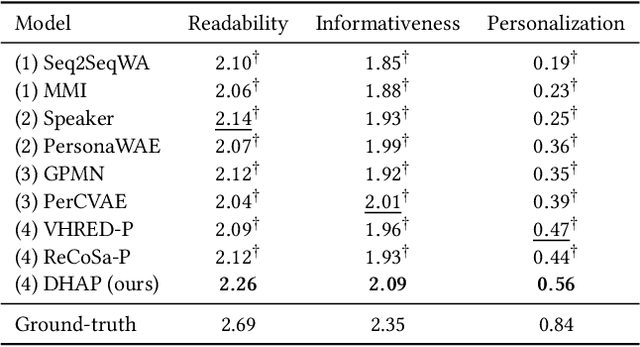
Personalized chatbots focus on endowing chatbots with a consistent personality to behave like real users, give more informative responses, and further act as personal assistants. Existing personalized approaches tried to incorporate several text descriptions as explicit user profiles. However, the acquisition of such explicit profiles is expensive and time-consuming, thus being impractical for large-scale real-world applications. Moreover, the restricted predefined profile neglects the language behavior of a real user and cannot be automatically updated together with the change of user interests. In this paper, we propose to learn implicit user profiles automatically from large-scale user dialogue history for building personalized chatbots. Specifically, leveraging the benefits of Transformer on language understanding, we train a personalized language model to construct a general user profile from the user's historical responses. To highlight the relevant historical responses to the input post, we further establish a key-value memory network of historical post-response pairs, and build a dynamic post-aware user profile. The dynamic profile mainly describes what and how the user has responded to similar posts in history. To explicitly utilize users' frequently used words, we design a personalized decoder to fuse two decoding strategies, including generating a word from the generic vocabulary and copying one word from the user's personalized vocabulary. Experiments on two real-world datasets show the significant improvement of our model compared with existing methods. Our code is available at https://github.com/zhengyima/DHAP
Pchatbot: A Large-Scale Dataset for Personalized Chatbot
Sep 28, 2020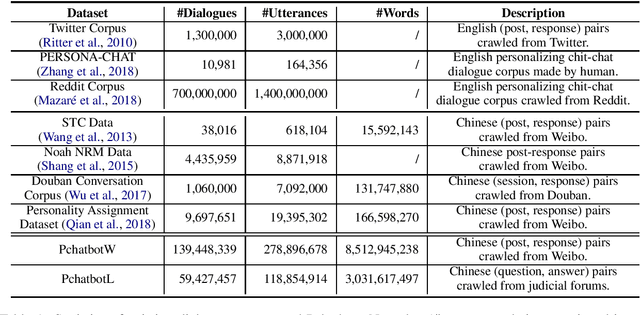
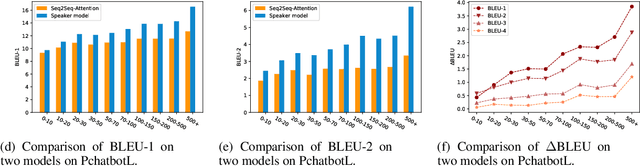
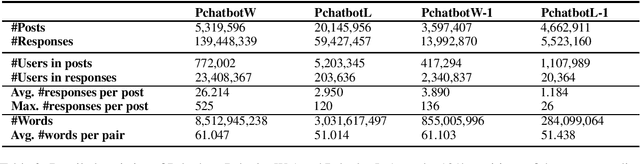

Natural language dialogue systems raise great attention recently. As many dialogue models are data-driven, high quality datasets are essential to these systems. In this paper, we introduce Pchatbot, a large scale dialogue dataset which contains two subsets collected from Weibo and Judical forums respectively. Different from existing datasets which only contain post-response pairs, we include anonymized user IDs as well as timestamps. This enables the development of personalized dialogue models which depend on the availability of users' historical conversations. Furthermore, the scale of Pchatbot is significantly larger than existing datasets, which might benefit the data-driven models. Our preliminary experimental study shows that a personalized chatbot model trained on Pchatbot outperforms the corresponding ad-hoc chatbot models. We also demonstrate that using larger dataset improves the quality of dialog models.