 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePchatbot: A Large-Scale Dataset for Personalized Chatbot
Paper and Code
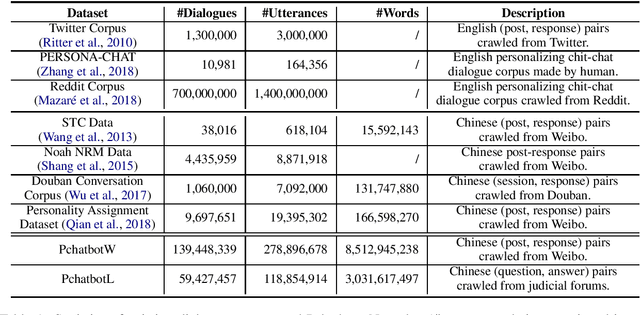
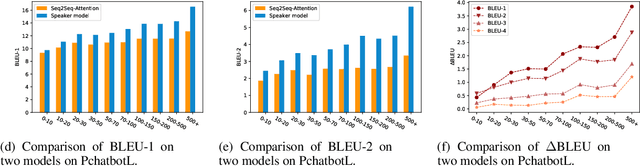
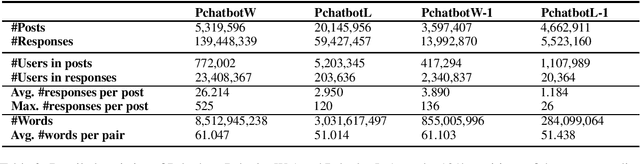

Natural language dialogue systems raise great attention recently. As many dialogue models are data-driven, high quality datasets are essential to these systems. In this paper, we introduce Pchatbot, a large scale dialogue dataset which contains two subsets collected from Weibo and Judical forums respectively. Different from existing datasets which only contain post-response pairs, we include anonymized user IDs as well as timestamps. This enables the development of personalized dialogue models which depend on the availability of users' historical conversations. Furthermore, the scale of Pchatbot is significantly larger than existing datasets, which might benefit the data-driven models. Our preliminary experimental study shows that a personalized chatbot model trained on Pchatbot outperforms the corresponding ad-hoc chatbot models. We also demonstrate that using larger dataset improves the quality of dialog models.