 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Models for Better Fine-Grained Named Entity Recognition
Paper and Code
Sep 15, 2020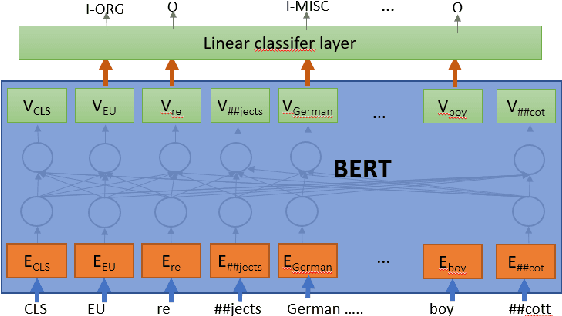
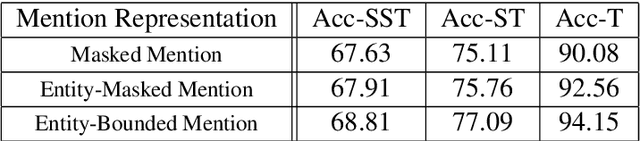
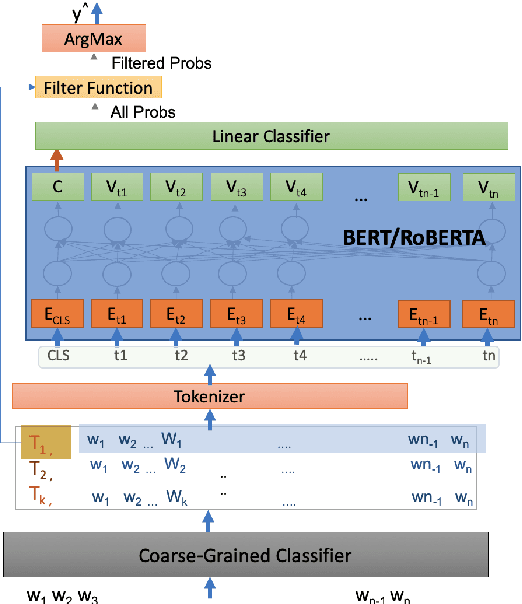
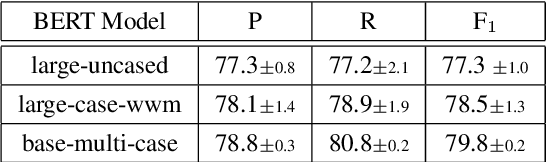
Named Entity Recognition (NER) is an essential precursor task for many natural language applications, such as relation extraction or event extraction. Much of the NER research has been done on datasets with few classes of entity types (e.g. PER, LOC, ORG, MISC), but many real world applications (disaster relief, complex event extraction, law enforcement) can benefit from a larger NER typeset. More recently, datasets were created that have hundreds to thousands of types of entities, sparking new lines of research (Sekine, 2008;Ling and Weld, 2012; Gillick et al., 2014; Choiet al., 2018). In this paper we present a cascaded approach to labeling fine-grained NER, applying to a newly released fine-grained NER dataset that was used in the TAC KBP 2019 evaluation (Ji et al., 2019), inspired by the fact that training data is available for some of the coarse labels. Using a combination of transformer networks, we show that performance can be improved by about 20 F1 absolute, as compared with the straightforward model built on the full fine-grained types, and show that, surprisingly, using course-labeled data in three languages leads to an improvement in the English data.