 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoTok: Regulating Information Flow for Capacity-Constrained Shared Visual Tokenization in Unified MLLMs
Feb 02, 2026Unified multimodal large language models (MLLMs) integrate image understanding and generation in a single framework, with the visual tokenizer acting as the sole interface that maps visual inputs into tokens for downstream tasks. However, existing shared-token designs are mostly architecture-driven and lack an explicit criterion for what information tokens should preserve to support both understanding and generation. Therefore, we introduce a capacity-constrained perspective, highlighting that in shared-token unified MLLMs the visual tokenizer behaves as a compute-bounded learner, so the token budget should prioritize reusable structure over hard-to-exploit high-entropy variations and redundancy. Motivated by this perspective, we propose InfoTok, an information-regularized visual tokenization mechanism grounded in the Information Bottleneck (IB) principle. InfoTok formulates tokenization as controlling information flow from images to shared tokens to multimodal outputs, yielding a principled trade-off between compression and task relevance via mutual-information regularization. We integrate InfoTok into three representative unified MLLMs without introducing any additional training data. Experiments show consistent improvements on both understanding and generation, supporting information-regularized tokenization as a principled foundation for learning a shared token space in unified MLLMs.
Video Compression with Hierarchical Temporal Neural Representation
Jan 25, 2026Video compression has recently benefited from implicit neural representations (INRs), which model videos as continuous functions. INRs offer compact storage and flexible reconstruction, providing a promising alternative to traditional codecs. However, most existing INR-based methods treat the temporal dimension as an independent input, limiting their ability to capture complex temporal dependencies. To address this, we propose a Hierarchical Temporal Neural Representation for Videos, TeNeRV. TeNeRV integrates short- and long-term dependencies through two key components. First, an Inter-Frame Feature Fusion (IFF) module aggregates features from adjacent frames, enforcing local temporal coherence and capturing fine-grained motion. Second, a GoP-Adaptive Modulation (GAM) mechanism partitions videos into Groups-of-Pictures and learns group-specific priors. The mechanism modulates network parameters, enabling adaptive representations across different GoPs. Extensive experiments demonstrate that TeNeRV consistently outperforms existing INR-based methods in rate-distortion performance, validating the effectiveness of our proposed approach.
Frequency-aware Neural Representation for Videos
Jan 25, 2026Implicit Neural Representations (INRs) have emerged as a promising paradigm for video compression. However, existing INR-based frameworks typically suffer from inherent spectral bias, which favors low-frequency components and leads to over-smoothed reconstructions and suboptimal rate-distortion performance. In this paper, we propose FaNeRV, a Frequency-aware Neural Representation for videos, which explicitly decouples low- and high-frequency components to enable efficient and faithful video reconstruction. FaNeRV introduces a multi-resolution supervision strategy that guides the network to progressively capture global structures and fine-grained textures through staged supervision . To further enhance high-frequency reconstruction, we propose a dynamic high-frequency injection mechanism that adaptively emphasizes challenging regions. In addition, we design a frequency-decomposed network module to improve feature modeling across different spectral bands. Extensive experiments on standard benchmarks demonstrate that FaNeRV significantly outperforms state-of-the-art INR methods and achieves competitive rate-distortion performance against traditional codecs.
MSNeRV: Neural Video Representation with Multi-Scale Feature Fusion
Jun 18, 2025Implicit Neural representations (INRs) have emerged as a promising approach for video compression, and have achieved comparable performance to the state-of-the-art codecs such as H.266/VVC. However, existing INR-based methods struggle to effectively represent detail-intensive and fast-changing video content. This limitation mainly stems from the underutilization of internal network features and the absence of video-specific considerations in network design. To address these challenges, we propose a multi-scale feature fusion framework, MSNeRV, for neural video representation. In the encoding stage, we enhance temporal consistency by employing temporal windows, and divide the video into multiple Groups of Pictures (GoPs), where a GoP-level grid is used for background representation. Additionally, we design a multi-scale spatial decoder with a scale-adaptive loss function to integrate multi-resolution and multi-frequency information. To further improve feature extraction, we introduce a multi-scale feature block that fully leverages hidden features. We evaluate MSNeRV on HEVC ClassB and UVG datasets for video representation and compression. Experimental results demonstrate that our model exhibits superior representation capability among INR-based approaches and surpasses VTM-23.7 (Random Access) in dynamic scenarios in terms of compression efficiency.
Scaling Vision Mamba Across Resolutions via Fractal Traversal
May 20, 2025Vision Mamba has recently emerged as a promising alternative to Transformer-based architectures, offering linear complexity in sequence length while maintaining strong modeling capacity. However, its adaptation to visual inputs is hindered by challenges in 2D-to-1D patch serialization and weak scalability across input resolutions. Existing serialization strategies such as raster scanning disrupt local spatial continuity and limit the model's ability to generalize across scales. In this paper, we propose FractalMamba++, a robust vision backbone that leverages fractal-based patch serialization via Hilbert curves to preserve spatial locality and enable seamless resolution adaptability. To address long-range dependency fading in high-resolution inputs, we further introduce a Cross-State Routing (CSR) mechanism that enhances global context propagation through selective state reuse. Additionally, we propose a Positional-Relation Capture (PRC) module to recover local adjacency disrupted by curve inflection points. Extensive experiments on image classification, semantic segmentation, object detection, and change detection demonstrate that FractalMamba++ consistently outperforms previous Mamba-based backbones, particularly under high-resolution settings.
UAR-NVC: A Unified AutoRegressive Framework for Memory-Efficient Neural Video Compression
Mar 04, 2025Implicit Neural Representations (INRs) have demonstrated significant potential in video compression by representing videos as neural networks. However, as the number of frames increases, the memory consumption for training and inference increases substantially, posing challenges in resource-constrained scenarios. Inspired by the success of traditional video compression frameworks, which process video frame by frame and can efficiently compress long videos, we adopt this modeling strategy for INRs to decrease memory consumption, while aiming to unify the frameworks from the perspective of timeline-based autoregressive modeling. In this work, we present a novel understanding of INR models from an autoregressive (AR) perspective and introduce a Unified AutoRegressive Framework for memory-efficient Neural Video Compression (UAR-NVC). UAR-NVC integrates timeline-based and INR-based neural video compression under a unified autoregressive paradigm. It partitions videos into several clips and processes each clip using a different INR model instance, leveraging the advantages of both compression frameworks while allowing seamless adaptation to either in form. To further reduce temporal redundancy between clips, we design two modules to optimize the initialization, training, and compression of these model parameters. UAR-NVC supports adjustable latencies by varying the clip length. Extensive experimental results demonstrate that UAR-NVC, with its flexible video clip setting, can adapt to resource-constrained environments and significantly improve performance compared to different baseline models.
CANeRV: Content Adaptive Neural Representation for Video Compression
Feb 10, 2025


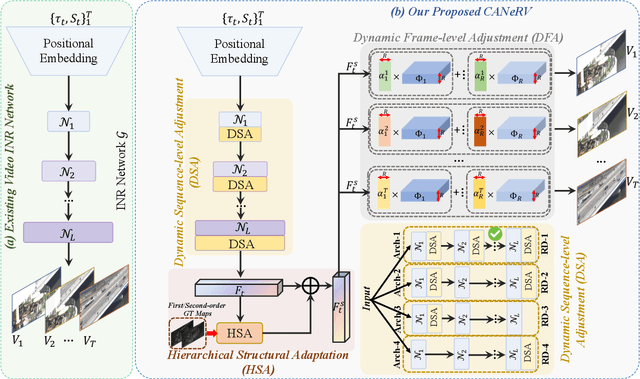
Recent advances in video compression introduce implicit neural representation (INR) based methods, which effectively capture global dependencies and characteristics of entire video sequences. Unlike traditional and deep learning based approaches, INR-based methods optimize network parameters from a global perspective, resulting in superior compression potential. However, most current INR methods utilize a fixed and uniform network architecture across all frames, limiting their adaptability to dynamic variations within and between video sequences. This often leads to suboptimal compression outcomes as these methods struggle to capture the distinct nuances and transitions in video content. To overcome these challenges, we propose Content Adaptive Neural Representation for Video Compression (CANeRV), an innovative INR-based video compression network that adaptively conducts structure optimisation based on the specific content of each video sequence. To better capture dynamic information across video sequences, we propose a dynamic sequence-level adjustment (DSA). Furthermore, to enhance the capture of dynamics between frames within a sequence, we implement a dynamic frame-level adjustment (DFA). {Finally, to effectively capture spatial structural information within video frames, thereby enhancing the detail restoration capabilities of CANeRV, we devise a structure level hierarchical structural adaptation (HSA).} Experimental results demonstrate that CANeRV can outperform both H.266/VVC and state-of-the-art INR-based video compression techniques across diverse video datasets.
Releasing the Parameter Latency of Neural Representation for High-Efficiency Video Compression
Oct 03, 2024



For decades, video compression technology has been a prominent research area. Traditional hybrid video compression framework and end-to-end frameworks continue to explore various intra- and inter-frame reference and prediction strategies based on discrete transforms and deep learning techniques. However, the emerging implicit neural representation (INR) technique models entire videos as basic units, automatically capturing intra-frame and inter-frame correlations and obtaining promising performance. INR uses a compact neural network to store video information in network parameters, effectively eliminating spatial and temporal redundancy in the original video. However, in this paper, our exploration and verification reveal that current INR video compression methods do not fully exploit their potential to preserve information. We investigate the potential of enhancing network parameter storage through parameter reuse. By deepening the network, we designed a feasible INR parameter reuse scheme to further improve compression performance. Extensive experimental results show that our method significantly enhances the rate-distortion performance of INR video compression.
Unleashing Parameter Potential of Neural Representation for Efficient Video Compression
Oct 02, 2024For decades, video compression technology has been a prominent research area. Traditional hybrid video compression framework and end-to-end frameworks continue to explore various intra- and inter-frame reference and prediction strategies based on discrete transforms and deep learning techniques. However, the emerging implicit neural representation (INR) technique models entire videos as basic units, automatically capturing intra-frame and inter-frame correlations and obtaining promising performance. INR uses a compact neural network to store video information in network parameters, effectively eliminating spatial and temporal redundancy in the original video. However, in this paper, our exploration and verification reveal that current INR video compression methods do not fully exploit their potential to preserve information. We investigate the potential of enhancing network parameter storage through parameter reuse. By deepening the network, we designed a feasible INR parameter reuse scheme to further improve compression performance. Extensive experimental results show that our method significantly enhances the rate-distortion performance of INR video compression.
Evaluating SAM2's Role in Camouflaged Object Detection: From SAM to SAM2
Jul 31, 2024



The Segment Anything Model (SAM), introduced by Meta AI Research as a generic object segmentation model, quickly garnered widespread attention and significantly influenced the academic community. To extend its application to video, Meta further develops Segment Anything Model 2 (SAM2), a unified model capable of both video and image segmentation. SAM2 shows notable improvements over its predecessor in terms of applicable domains, promptable segmentation accuracy, and running speed. However, this report reveals a decline in SAM2's ability to perceive different objects in images without prompts in its auto mode, compared to SAM. Specifically, we employ the challenging task of camouflaged object detection to assess this performance decrease, hoping to inspire further exploration of the SAM model family by researchers. The results of this paper are provided in \url{https://github.com/luckybird1994/SAMCOD}.