 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Learning-Based Non-Linear Model Predictive Control through Recurrent Neural Network Modeling
Mar 25, 2026The practical deployment of nonlinear model predictive control (NMPC) is often limited by online computation: solving a nonlinear program at high control rates can be expensive on embedded hardware, especially when models are complex or horizons are long. Learning-based NMPC approximations shift this computation offline but typically demand large expert datasets and costly training. We propose Sequential-AMPC, a sequential neural policy that generates MPC candidate control sequences by sharing parameters across the prediction horizon. For deployment, we wrap the policy in a safety-augmented online evaluation and fallback mechanism, yielding Safe Sequential-AMPC. Compared to a naive feedforward policy baseline across several benchmarks, Sequential-AMPC requires substantially fewer expert MPC rollouts and yields candidate sequences with higher feasibility rates and improved closed-loop safety. On high-dimensional systems, it also exhibits better learning dynamics and performance in fewer epochs while maintaining stable validation improvement where the feedforward baseline can stagnate.
Synaptic Activation and Dual Liquid Dynamics for Interpretable Bio-Inspired Models
Feb 13, 2026In this paper, we present a unified framework for various bio-inspired models to better understand their structural and functional differences. We show that liquid-capacitance-extended models lead to interpretable behavior even in dense, all-to-all recurrent neural network (RNN) policies. We further demonstrate that incorporating chemical synapses improves interpretability and that combining chemical synapses with synaptic activation yields the most accurate and interpretable RNN models. To assess the accuracy and interpretability of these RNN policies, we consider the challenging lane-keeping control task and evaluate performance across multiple metrics, including turn-weighted validation loss, neural activity during driving, absolute correlation between neural activity and road trajectory, saliency maps of the networks' attention, and the robustness of their saliency maps measured by the structural similarity index.
Online Fine-Tuning of Pretrained Controllers for Autonomous Driving via Real-Time Recurrent RL
Feb 03, 2026Deploying pretrained policies in real-world applications presents substantial challenges that fundamentally limit the practical applicability of learning-based control systems. When autonomous systems encounter environmental changes in system dynamics, sensor drift, or task objectives, fixed policies rapidly degrade in performance. We show that employing Real-Time Recurrent Reinforcement Learning (RTRRL), a biologically plausible algorithm for online adaptation, can effectively fine-tune a pretrained policy to improve autonomous agents' performance on driving tasks. We further show that RTRRL synergizes with a recent biologically inspired recurrent network model, the Liquid-Resistance Liquid-Capacitance RNN. We demonstrate the effectiveness of this closed-loop approach in a simulated CarRacing environment and in a real-world line-following task with a RoboRacer car equipped with an event camera.
Differential Gated Self-Attention
May 29, 2025Transformers excel across a large variety of tasks but remain susceptible to corrupted inputs, since standard self-attention treats all query-key interactions uniformly. Inspired by lateral inhibition in biological neural circuits and building on the recent use by the Differential Transformer's use of two parallel softmax subtraction for noise cancellation, we propose Multihead Differential Gated Self-Attention (M-DGSA) that learns per-head input-dependent gating to dynamically suppress attention noise. Each head splits into excitatory and inhibitory branches whose dual softmax maps are fused by a sigmoid gate predicted from the token embedding, yielding a context-aware contrast enhancement. M-DGSA integrates seamlessly into existing Transformer stacks with minimal computational overhead. We evaluate on both vision and language benchmarks, demonstrating consistent robustness gains over vanilla Transformer, Vision Transformer, and Differential Transformer baselines. Our contributions are (i) a novel input-dependent gating mechanism for self-attention grounded in lateral inhibition, (ii) a principled synthesis of biological contrast-enhancement and self-attention theory, and (iii) comprehensive experiments demonstrating noise resilience and cross-domain applicability.
Scaling Up Liquid-Resistance Liquid-Capacitance Networks for Efficient Sequence Modeling
May 29, 2025We present LrcSSM, a $\textit{nonlinear}$ recurrent model that processes long sequences as fast as today's linear state-space layers. By forcing the state-transition matrix to be diagonal and learned at every step, the full sequence can be solved in parallel with a single prefix-scan, giving $\mathcal{O}(TD)$ time and memory and only $\mathcal{O}(\log T)$ sequential depth, for input-sequence length $T$ and a state dimension $D$. Moreover, LrcSSM offers a formal gradient-stability guarantee that other input-varying systems such as Liquid-S4 and Mamba do not provide. Lastly, for network depth $L$, as the forward and backward passes cost $\Theta(T\,D\,L)$ FLOPs, with its low sequential depth and parameter count $\Theta(D\,L)$, the model follows the compute-optimal scaling law regime ($\beta \approx 0.42$) recently observed for Mamba, outperforming quadratic-attention Transformers at equal compute while avoiding the memory overhead of FFT-based long convolutions. We show that on a series of long-range forecasting tasks, LrcSSM outperforms LRU, S5 and Mamba.
Depth Matters: Multimodal RGB-D Perception for Robust Autonomous Agents
Mar 20, 2025



Autonomous agents that rely purely on perception to make real-time control decisions require efficient and robust architectures. In this work, we demonstrate that augmenting RGB input with depth information significantly enhances our agents' ability to predict steering commands compared to using RGB alone. We benchmark lightweight recurrent controllers that leverage the fused RGB-D features for sequential decision-making. To train our models, we collect high-quality data using a small-scale autonomous car controlled by an expert driver via a physical steering wheel, capturing varying levels of steering difficulty. Our models, trained under diverse configurations, were successfully deployed on real hardware. Specifically, our findings reveal that the early fusion of depth data results in a highly robust controller, which remains effective even with frame drops and increased noise levels, without compromising the network's focus on the task.
MMDVS-LF: A Multi-Modal Dynamic-Vision-Sensor Line Following Dataset
Sep 26, 2024



Dynamic Vision Sensors (DVS), offer a unique advantage in control applications, due to their high temporal resolution, and asynchronous event-based data. Still, their adoption in machine learning algorithms remains limited. To address this gap, and promote the development of models that leverage the specific characteristics of DVS data, we introduce the Multi-Modal Dynamic-Vision-Sensor Line Following dataset (MMDVS-LF). This comprehensive dataset, is the first to integrate multiple sensor modalities, including DVS recordings, RGB video, odometry, and Inertial Measurement Unit (IMU) data, from a small-scale standardized vehicle. Additionally, the dataset includes eye-tracking and demographic data of drivers performing a Line Following task on a track. With its diverse range of data, MMDVS-LF opens new opportunities for developing deep learning algorithms, and conducting data science projects across various domains, supporting innovation in autonomous systems and control applications.
Conditionally Risk-Averse Contextual Bandits
Oct 24, 2022



We desire to apply contextual bandits to scenarios where average-case statistical guarantees are inadequate. Happily, we discover the composition of reduction to online regression and expectile loss is analytically tractable, computationally convenient, and empirically effective. The result is the first risk-averse contextual bandit algorithm with an online regret guarantee. We state our precise regret guarantee and conduct experiments from diverse scenarios in dynamic pricing, inventory management, and self-tuning software; including results from a production exascale cloud data processing system.
Decaying Clipping Range in Proximal Policy Optimization
Feb 20, 2021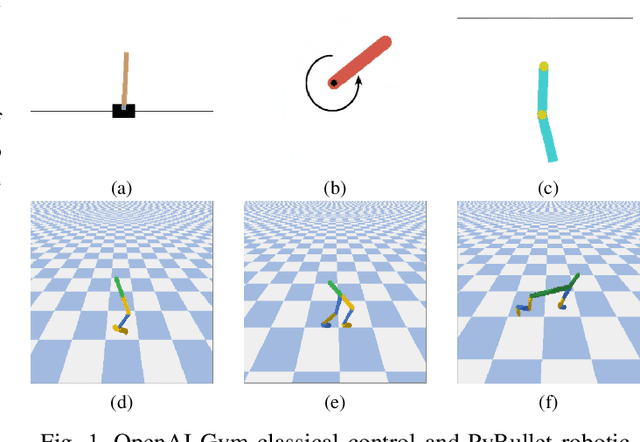
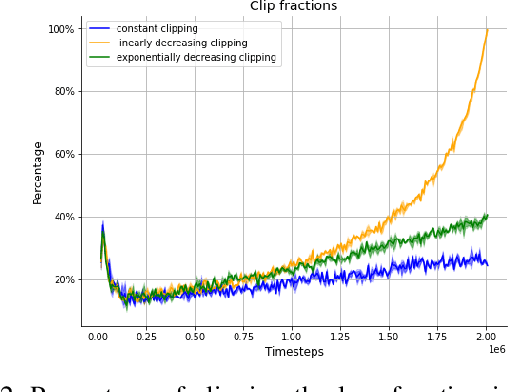
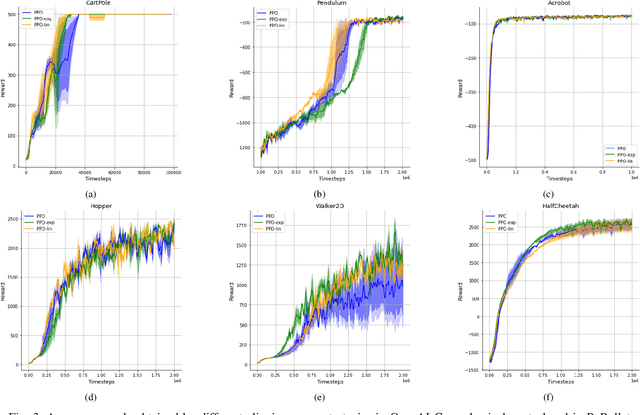

Proximal Policy Optimization (PPO) is among the most widely used algorithms in reinforcement learning, which achieves state-of-the-art performance in many challenging problems. The keys to its success are the reliable policy updates through the clipping mechanism and the multiple epochs of minibatch updates. The aim of this research is to give new simple but effective alternatives to the former. For this, we propose linearly and exponentially decaying clipping range approaches throughout the training. With these, we would like to provide higher exploration at the beginning and stronger restrictions at the end of the learning phase. We investigate their performance in several classical control and locomotive robotic environments. During the analysis, we found that they influence the achieved rewards and are effective alternatives to the constant clipping method in many reinforcement learning tasks.
Importance of Environment Design in Reinforcement Learning: A Study of a Robotic Environment
Feb 20, 2021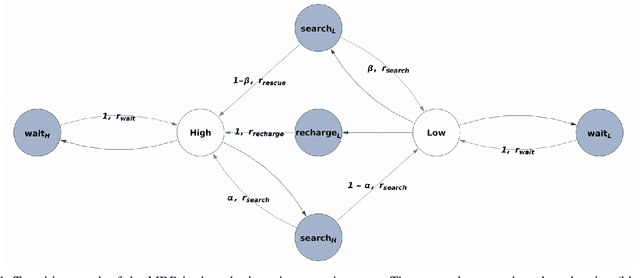
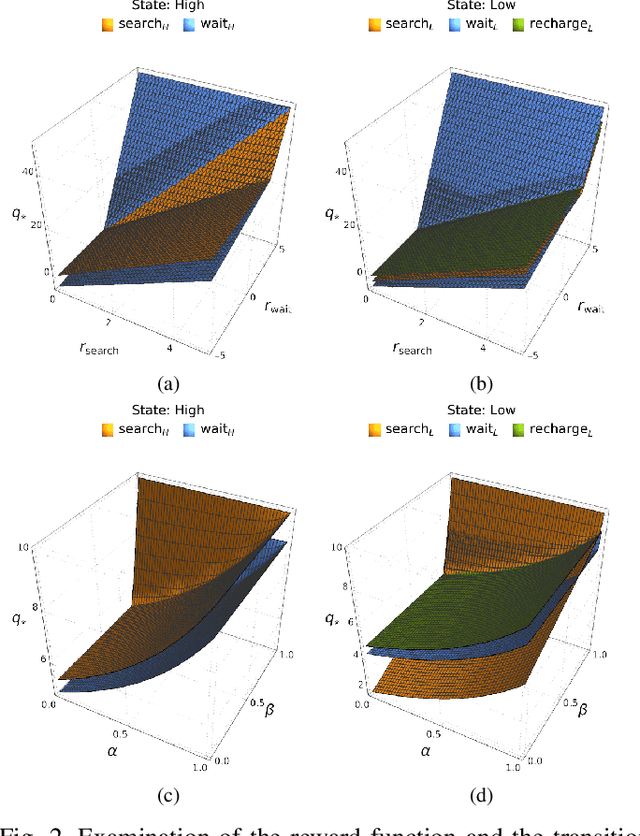
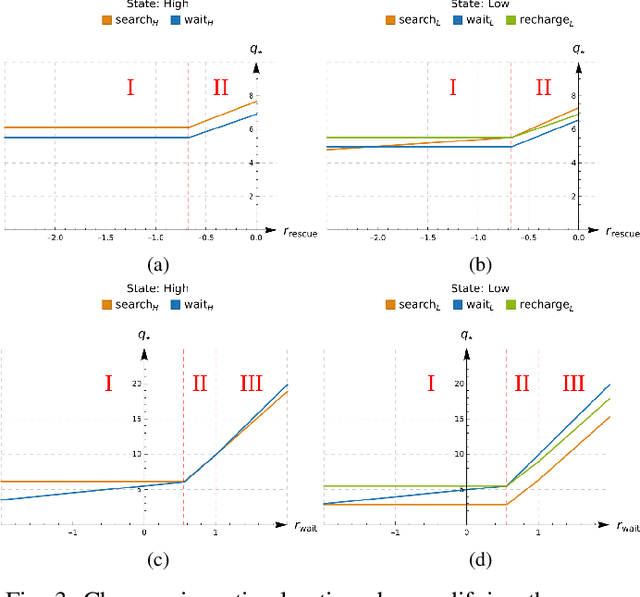
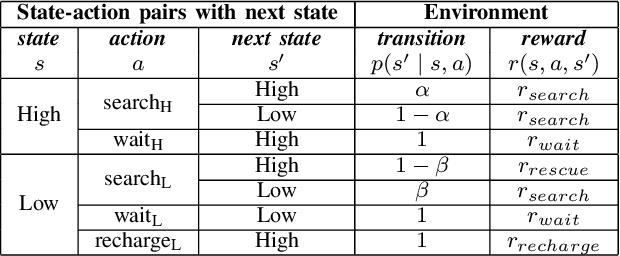
An in-depth understanding of the particular environment is crucial in reinforcement learning (RL). To address this challenge, the decision-making process of a mobile collaborative robotic assistant modeled by the Markov decision process (MDP) framework is studied in this paper. The optimal state-action combinations of the MDP are calculated with the non-linear Bellman optimality equations. This system of equations can be solved with relative ease by the computational power of Wolfram Mathematica, where the obtained optimal action-values results point to the optimal policy. Unlike other RL algorithms, this methodology does not approximate the optimal behavior, it provides the exact, explicit solution, which provides a strong foundation for our study. With this, we offer new insights into understanding the action selection mechanisms in RL. During the analysis of the robotic environment, we present various small modifications on the very same schema that lead to different optimal policies. Finally, we emphasize that beyond building efficient RL algorithms, only the proper design of the environment can ensure the desired results.