 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance of Environment Design in Reinforcement Learning: A Study of a Robotic Environment
Paper and Code
Feb 20, 2021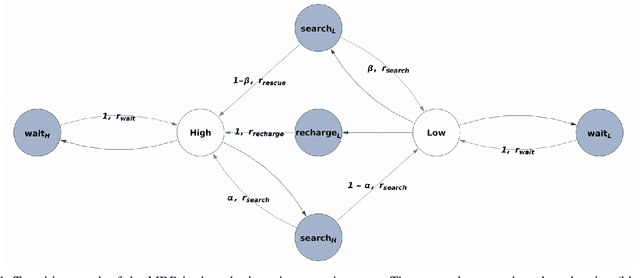
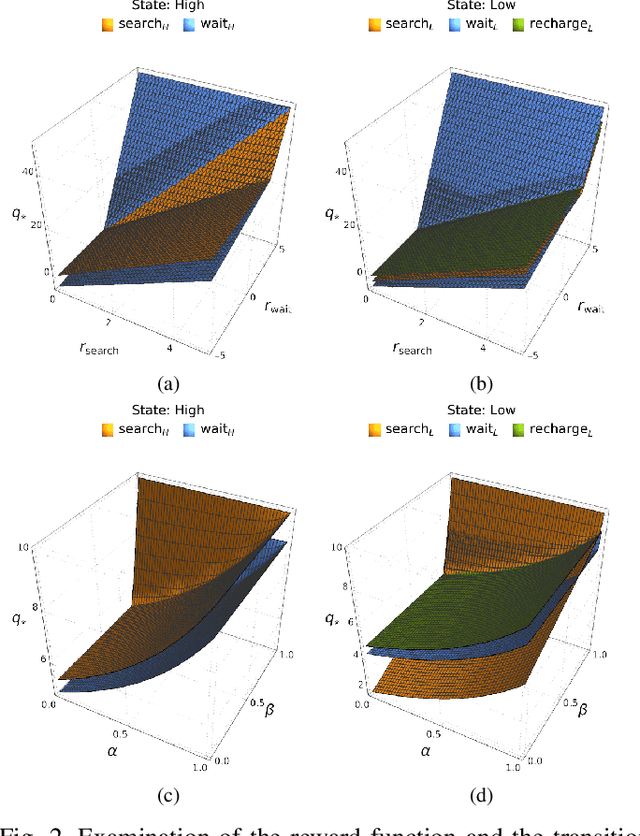
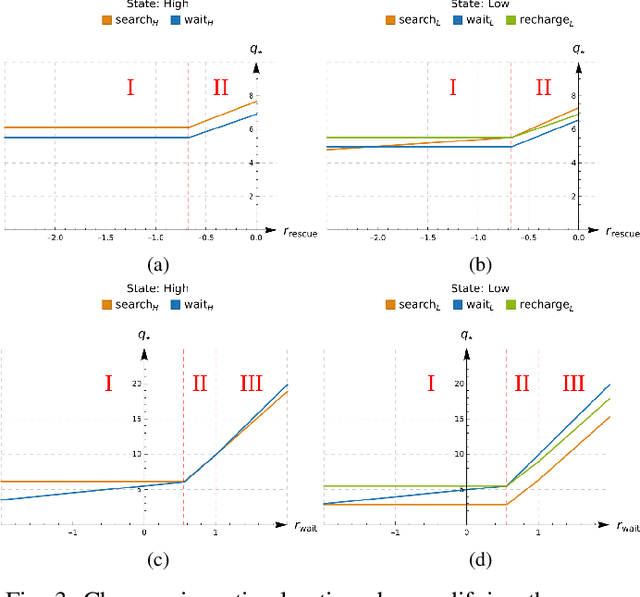
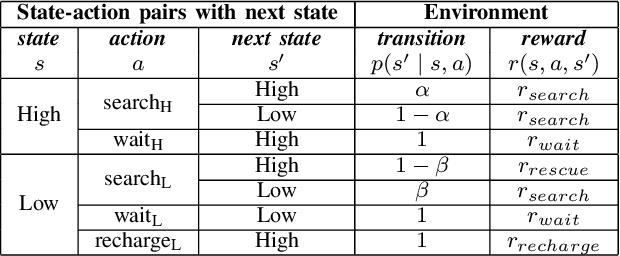
An in-depth understanding of the particular environment is crucial in reinforcement learning (RL). To address this challenge, the decision-making process of a mobile collaborative robotic assistant modeled by the Markov decision process (MDP) framework is studied in this paper. The optimal state-action combinations of the MDP are calculated with the non-linear Bellman optimality equations. This system of equations can be solved with relative ease by the computational power of Wolfram Mathematica, where the obtained optimal action-values results point to the optimal policy. Unlike other RL algorithms, this methodology does not approximate the optimal behavior, it provides the exact, explicit solution, which provides a strong foundation for our study. With this, we offer new insights into understanding the action selection mechanisms in RL. During the analysis of the robotic environment, we present various small modifications on the very same schema that lead to different optimal policies. Finally, we emphasize that beyond building efficient RL algorithms, only the proper design of the environment can ensure the desired results.