 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecaying Clipping Range in Proximal Policy Optimization
Feb 20, 2021
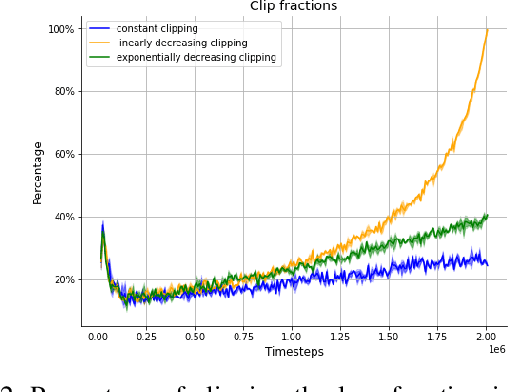
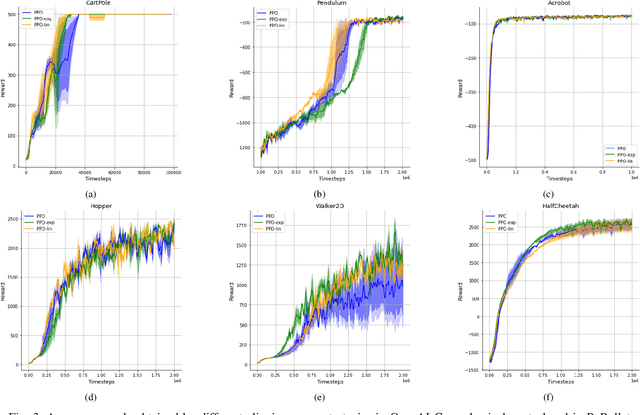

Proximal Policy Optimization (PPO) is among the most widely used algorithms in reinforcement learning, which achieves state-of-the-art performance in many challenging problems. The keys to its success are the reliable policy updates through the clipping mechanism and the multiple epochs of minibatch updates. The aim of this research is to give new simple but effective alternatives to the former. For this, we propose linearly and exponentially decaying clipping range approaches throughout the training. With these, we would like to provide higher exploration at the beginning and stronger restrictions at the end of the learning phase. We investigate their performance in several classical control and locomotive robotic environments. During the analysis, we found that they influence the achieved rewards and are effective alternatives to the constant clipping method in many reinforcement learning tasks.
Importance of Environment Design in Reinforcement Learning: A Study of a Robotic Environment
Feb 20, 2021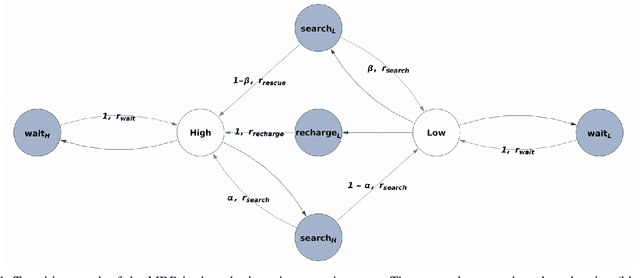
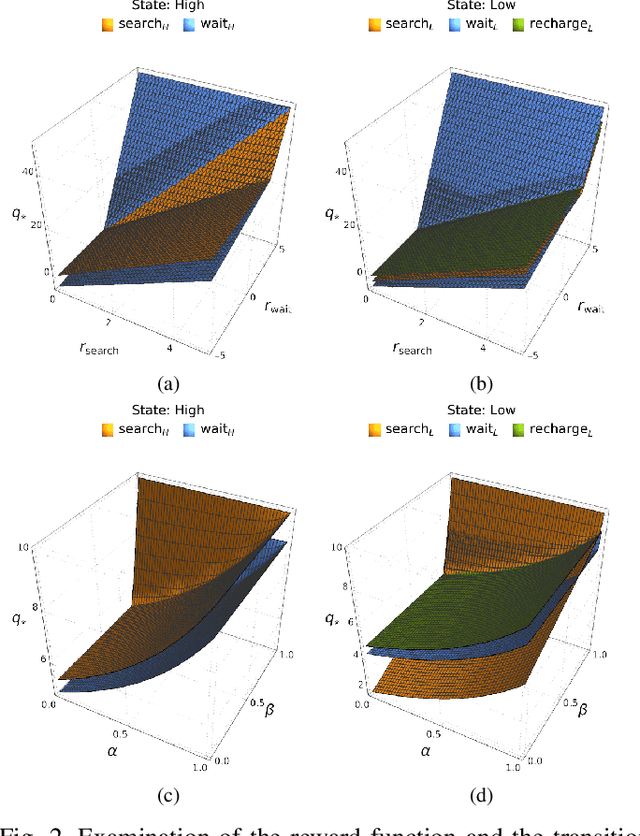
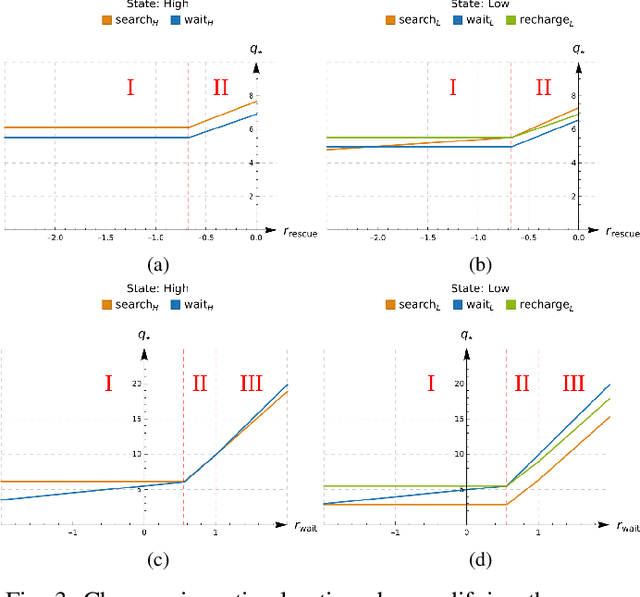
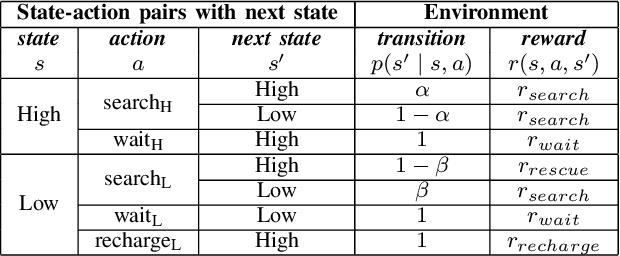
An in-depth understanding of the particular environment is crucial in reinforcement learning (RL). To address this challenge, the decision-making process of a mobile collaborative robotic assistant modeled by the Markov decision process (MDP) framework is studied in this paper. The optimal state-action combinations of the MDP are calculated with the non-linear Bellman optimality equations. This system of equations can be solved with relative ease by the computational power of Wolfram Mathematica, where the obtained optimal action-values results point to the optimal policy. Unlike other RL algorithms, this methodology does not approximate the optimal behavior, it provides the exact, explicit solution, which provides a strong foundation for our study. With this, we offer new insights into understanding the action selection mechanisms in RL. During the analysis of the robotic environment, we present various small modifications on the very same schema that lead to different optimal policies. Finally, we emphasize that beyond building efficient RL algorithms, only the proper design of the environment can ensure the desired results.