 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Fine-Tuning of Pretrained Controllers for Autonomous Driving via Real-Time Recurrent RL
Feb 03, 2026Deploying pretrained policies in real-world applications presents substantial challenges that fundamentally limit the practical applicability of learning-based control systems. When autonomous systems encounter environmental changes in system dynamics, sensor drift, or task objectives, fixed policies rapidly degrade in performance. We show that employing Real-Time Recurrent Reinforcement Learning (RTRRL), a biologically plausible algorithm for online adaptation, can effectively fine-tune a pretrained policy to improve autonomous agents' performance on driving tasks. We further show that RTRRL synergizes with a recent biologically inspired recurrent network model, the Liquid-Resistance Liquid-Capacitance RNN. We demonstrate the effectiveness of this closed-loop approach in a simulated CarRacing environment and in a real-world line-following task with a RoboRacer car equipped with an event camera.
Depth Matters: Multimodal RGB-D Perception for Robust Autonomous Agents
Mar 20, 2025



Autonomous agents that rely purely on perception to make real-time control decisions require efficient and robust architectures. In this work, we demonstrate that augmenting RGB input with depth information significantly enhances our agents' ability to predict steering commands compared to using RGB alone. We benchmark lightweight recurrent controllers that leverage the fused RGB-D features for sequential decision-making. To train our models, we collect high-quality data using a small-scale autonomous car controlled by an expert driver via a physical steering wheel, capturing varying levels of steering difficulty. Our models, trained under diverse configurations, were successfully deployed on real hardware. Specifically, our findings reveal that the early fusion of depth data results in a highly robust controller, which remains effective even with frame drops and increased noise levels, without compromising the network's focus on the task.
MMDVS-LF: A Multi-Modal Dynamic-Vision-Sensor Line Following Dataset
Sep 26, 2024



Dynamic Vision Sensors (DVS), offer a unique advantage in control applications, due to their high temporal resolution, and asynchronous event-based data. Still, their adoption in machine learning algorithms remains limited. To address this gap, and promote the development of models that leverage the specific characteristics of DVS data, we introduce the Multi-Modal Dynamic-Vision-Sensor Line Following dataset (MMDVS-LF). This comprehensive dataset, is the first to integrate multiple sensor modalities, including DVS recordings, RGB video, odometry, and Inertial Measurement Unit (IMU) data, from a small-scale standardized vehicle. Additionally, the dataset includes eye-tracking and demographic data of drivers performing a Line Following task on a track. With its diverse range of data, MMDVS-LF opens new opportunities for developing deep learning algorithms, and conducting data science projects across various domains, supporting innovation in autonomous systems and control applications.
Enhancing Robot Learning through Learned Human-Attention Feature Maps
Aug 29, 2023
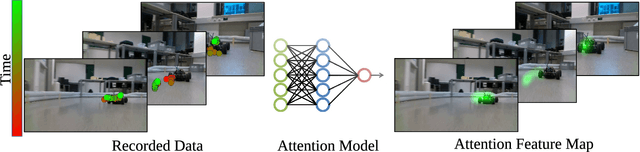


Robust and efficient learning remains a challenging problem in robotics, in particular with complex visual inputs. Inspired by human attention mechanism, with which we quickly process complex visual scenes and react to changes in the environment, we think that embedding auxiliary information about focus point into robot learning would enhance efficiency and robustness of the learning process. In this paper, we propose a novel approach to model and emulate the human attention with an approximate prediction model. We then leverage this output and feed it as a structured auxiliary feature map into downstream learning tasks. We validate this idea by learning a prediction model from human-gaze recordings of manual driving in the real world. We test our approach on two learning tasks - object detection and imitation learning. Our experiments demonstrate that the inclusion of predicted human attention leads to improved robustness of the trained models to out-of-distribution samples and faster learning in low-data regime settings. Our work highlights the potential of incorporating structured auxiliary information in representation learning for robotics and opens up new avenues for research in this direction. All code and data are available online.