 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up Psychology via Scientific Regret Minimization: A Case Study in Moral Decision-Making
Paper and Code
Oct 16, 2019
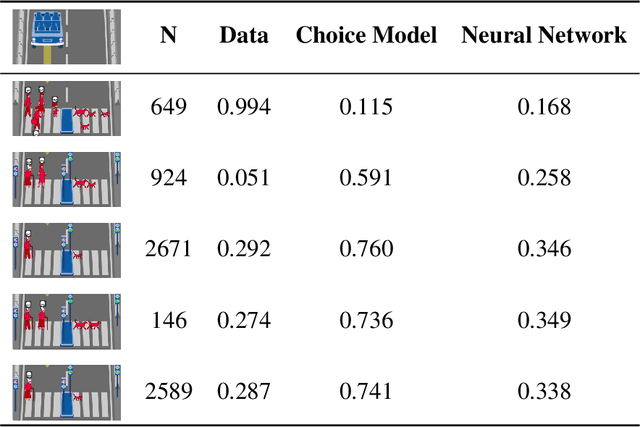
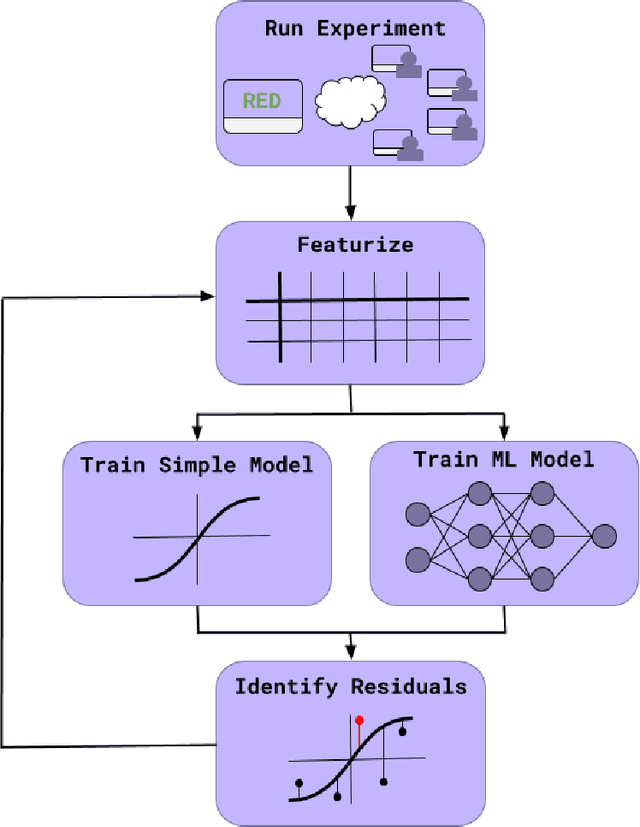
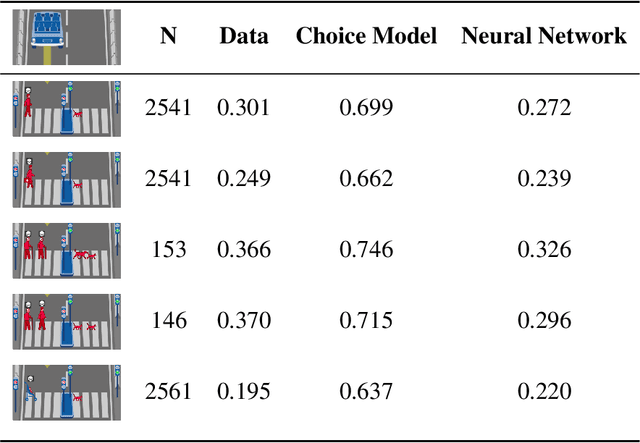
Do large datasets provide value to psychologists? Without a systematic methodology for working with such datasets, there is a valid concern that analyses will produce noise artifacts rather than true effects. In this paper, we offer a way to enable researchers to systematically build models and identify novel phenomena in large datasets. One traditional approach is to analyze the residuals of models---the biggest errors they make in predicting the data---to discover what might be missing from those models. However, once a dataset is sufficiently large, machine learning algorithms approximate the true underlying function better than the data, suggesting instead that the predictions of these data-driven models should be used to guide model-building. We call this approach "Scientific Regret Minimization" (SRM) as it focuses on minimizing errors for cases that we know should have been predictable. We demonstrate this methodology on a subset of the Moral Machine dataset, a public collection of roughly forty million moral decisions. Using SRM, we found that incorporating a set of deontological principles that capture dimensions along which groups of agents can vary (e.g. sex and age) improves a computational model of human moral judgment. Furthermore, we were able to identify and independently validate three interesting moral phenomena: criminal dehumanization, age of responsibility, and asymmetric notions of responsibility.