 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Language Understanding from Screenshots
Paper and Code
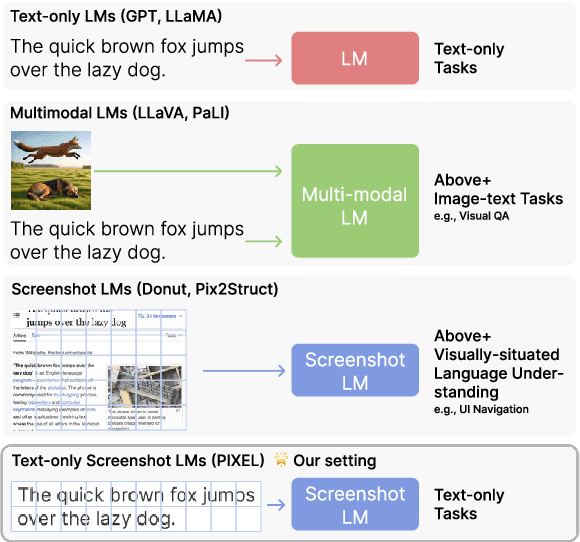
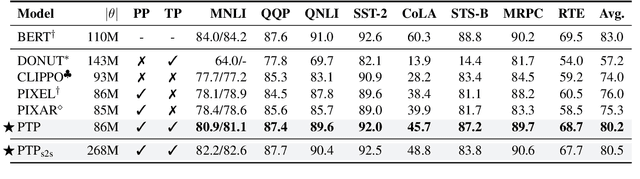
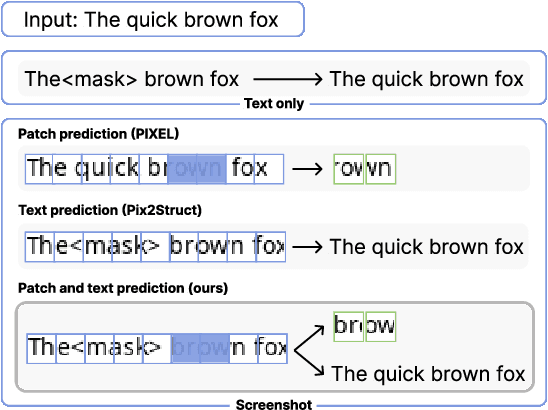
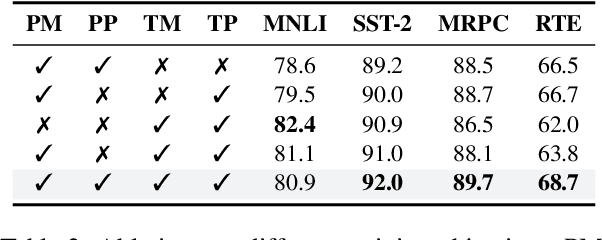
An emerging family of language models (LMs), capable of processing both text and images within a single visual view, has the promise to unlock complex tasks such as chart understanding and UI navigation. We refer to these models as screenshot language models. Despite their appeal, existing screenshot LMs substantially lag behind text-only models on language understanding tasks. To close this gap, we adopt a simplified setting where the model inputs are plain-text-rendered screenshots, and we focus on improving the text ability of screenshot LMs. We propose a novel Patch-and-Text Prediction (PTP) objective, which masks and recovers both image patches of screenshots and text within screenshots. We also conduct extensive ablation studies on masking rates and patch sizes, as well as designs for improving training stability. Our pre-trained model, while solely taking visual inputs, achieves comparable performance with BERT on 6 out of 8 GLUE tasks (within 2%) and improves up to 8% over prior work. Additionally, we extend PTP to train autoregressive screenshot LMs and demonstrate its effectiveness--our models can significantly reduce perplexity by utilizing the screenshot context. Together, we hope our findings can inspire future research on developing powerful screenshot LMs and extending their reach to broader applications.