 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo Wider Instead of Deeper
Jul 29, 2021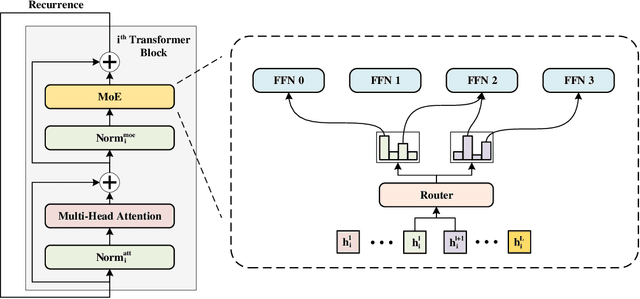
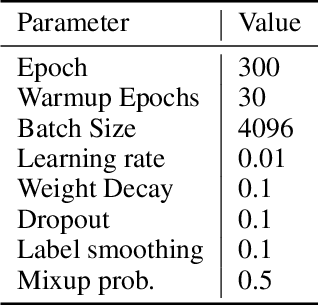
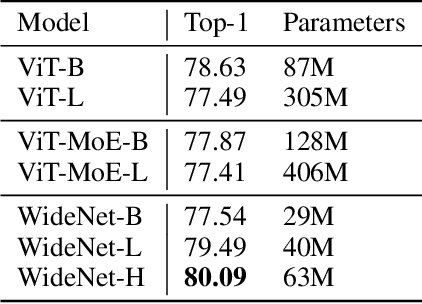
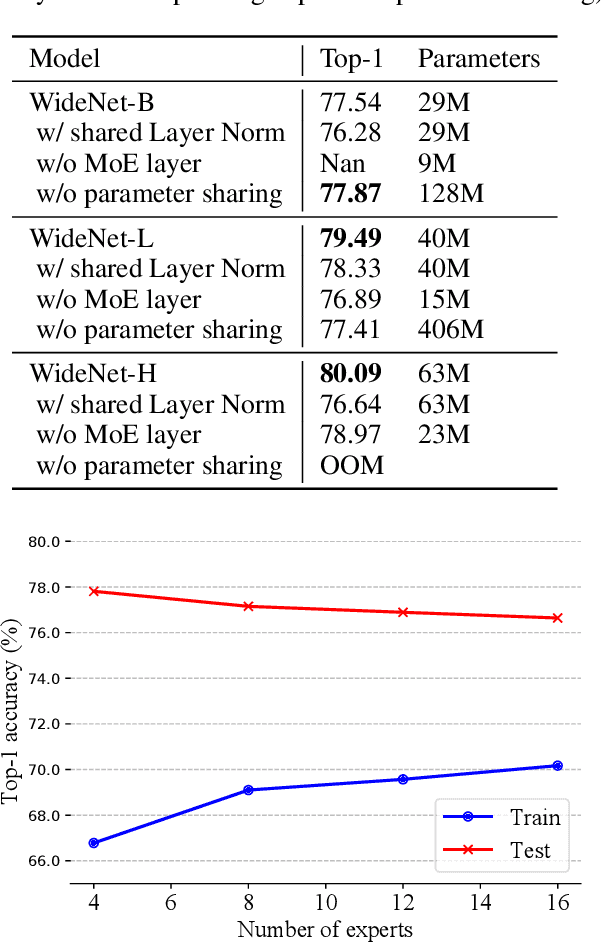
The transformer has recently achieved impressive results on various tasks. To further improve the effectiveness and efficiency of the transformer, there are two trains of thought among existing works: (1) going wider by scaling to more trainable parameters; (2) going shallower by parameter sharing or model compressing along with the depth. However, larger models usually do not scale well when fewer tokens are available to train, and advanced parallelisms are required when the model is extremely large. Smaller models usually achieve inferior performance compared to the original transformer model due to the loss of representation power. In this paper, to achieve better performance with fewer trainable parameters, we propose a framework to deploy trainable parameters efficiently, by going wider instead of deeper. Specially, we scale along model width by replacing feed-forward network (FFN) with mixture-of-experts (MoE). We then share the MoE layers across transformer blocks using individual layer normalization. Such deployment plays the role to transform various semantic representations, which makes the model more parameter-efficient and effective. To evaluate our framework, we design WideNet and evaluate it on ImageNet-1K. Our best model outperforms Vision Transformer (ViT) by $1.46\%$ with $0.72 \times$ trainable parameters. Using $0.46 \times$ and $0.13 \times$ parameters, our WideNet can still surpass ViT and ViT-MoE by $0.83\%$ and $2.08\%$, respectively.