 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHO-Gaussian: Hybrid Optimization of 3D Gaussian Splatting for Urban Scenes
Mar 29, 2024


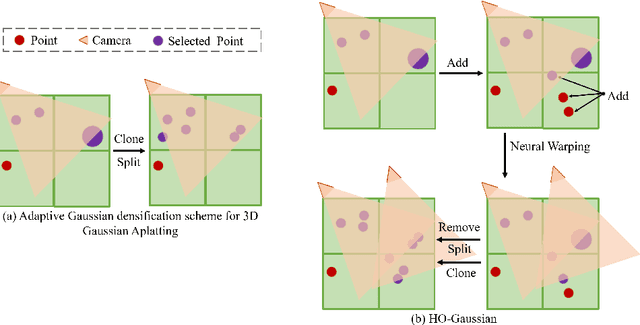
The rapid growth of 3D Gaussian Splatting (3DGS) has revolutionized neural rendering, enabling real-time production of high-quality renderings. However, the previous 3DGS-based methods have limitations in urban scenes due to reliance on initial Structure-from-Motion(SfM) points and difficulties in rendering distant, sky and low-texture areas. To overcome these challenges, we propose a hybrid optimization method named HO-Gaussian, which combines a grid-based volume with the 3DGS pipeline. HO-Gaussian eliminates the dependency on SfM point initialization, allowing for rendering of urban scenes, and incorporates the Point Densitification to enhance rendering quality in problematic regions during training. Furthermore, we introduce Gaussian Direction Encoding as an alternative for spherical harmonics in the rendering pipeline, which enables view-dependent color representation. To account for multi-camera systems, we introduce neural warping to enhance object consistency across different cameras. Experimental results on widely used autonomous driving datasets demonstrate that HO-Gaussian achieves photo-realistic rendering in real-time on multi-camera urban datasets.
DGNR: Density-Guided Neural Point Rendering of Large Driving Scenes
Nov 28, 2023



Despite the recent success of Neural Radiance Field (NeRF), it is still challenging to render large-scale driving scenes with long trajectories, particularly when the rendering quality and efficiency are in high demand. Existing methods for such scenes usually involve with spatial warping, geometric supervision from zero-shot normal or depth estimation, or scene division strategies, where the synthesized views are often blurry or fail to meet the requirement of efficient rendering. To address the above challenges, this paper presents a novel framework that learns a density space from the scenes to guide the construction of a point-based renderer, dubbed as DGNR (Density-Guided Neural Rendering). In DGNR, geometric priors are no longer needed, which can be intrinsically learned from the density space through volumetric rendering. Specifically, we make use of a differentiable renderer to synthesize images from the neural density features obtained from the learned density space. A density-based fusion module and geometric regularization are proposed to optimize the density space. By conducting experiments on a widely used autonomous driving dataset, we have validated the effectiveness of DGNR in synthesizing photorealistic driving scenes and achieving real-time capable rendering.
READ: Large-Scale Neural Scene Rendering for Autonomous Driving
May 11, 2022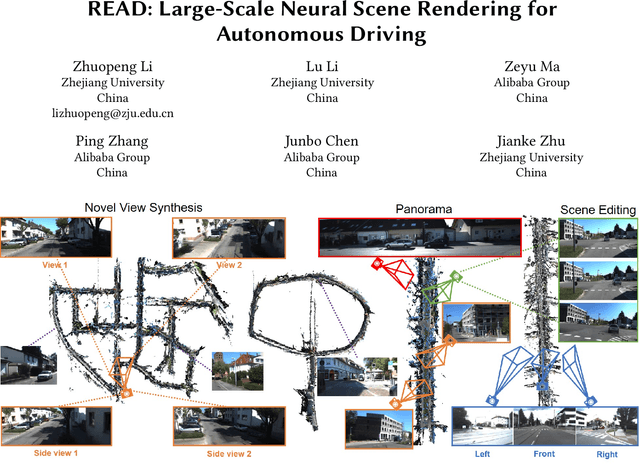
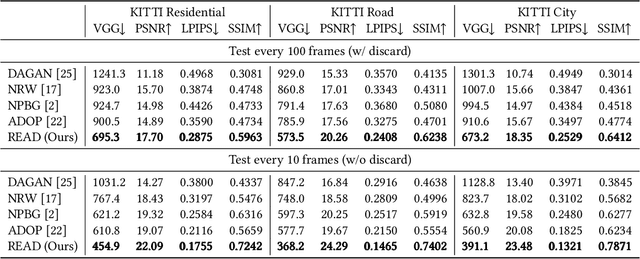
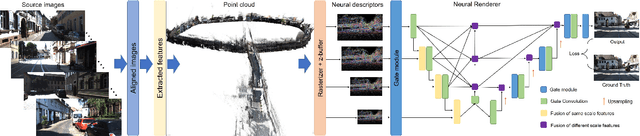
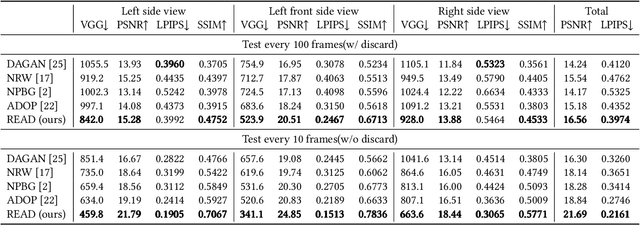
Synthesizing free-view photo-realistic images is an important task in multimedia. With the development of advanced driver assistance systems~(ADAS) and their applications in autonomous vehicles, experimenting with different scenarios becomes a challenge. Although the photo-realistic street scenes can be synthesized by image-to-image translation methods, which cannot produce coherent scenes due to the lack of 3D information. In this paper, a large-scale neural rendering method is proposed to synthesize the autonomous driving scene~(READ), which makes it possible to synthesize large-scale driving scenarios on a PC through a variety of sampling schemes. In order to represent driving scenarios, we propose an {\omega} rendering network to learn neural descriptors from sparse point clouds. Our model can not only synthesize realistic driving scenes but also stitch and edit driving scenes. Experiments show that our model performs well in large-scale driving scenarios.