 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Distributional Temporal Difference Learning with Linear Function Approximation
Nov 16, 2025
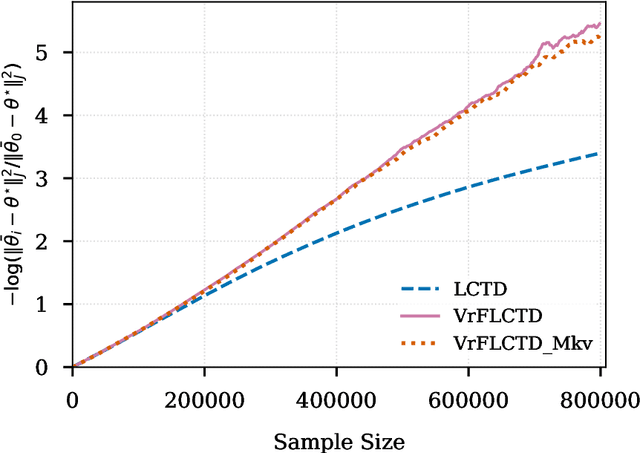
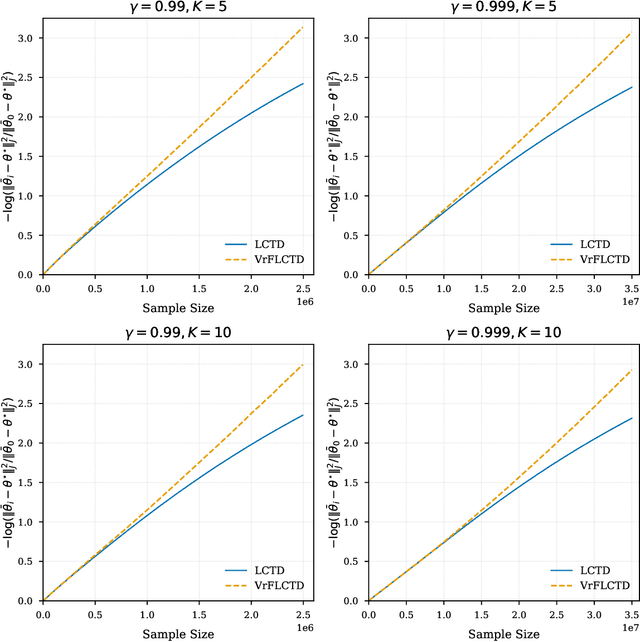
In this paper, we study the finite-sample statistical rates of distributional temporal difference (TD) learning with linear function approximation. The purpose of distributional TD learning is to estimate the return distribution of a discounted Markov decision process for a given policy. Previous works on statistical analysis of distributional TD learning focus mainly on the tabular case. We first consider the linear function approximation setting and conduct a fine-grained analysis of the linear-categorical Bellman equation. Building on this analysis, we further incorporate variance reduction techniques in our new algorithms to establish tight sample complexity bounds independent of the support size $K$ when $K$ is large. Our theoretical results imply that, when employing distributional TD learning with linear function approximation, learning the full distribution of the return function from streaming data is no more difficult than learning its expectation. This work provide new insights into the statistical efficiency of distributional reinforcement learning algorithms.
Finite Sample Analysis of Distributional TD Learning with Linear Function Approximation
Feb 20, 2025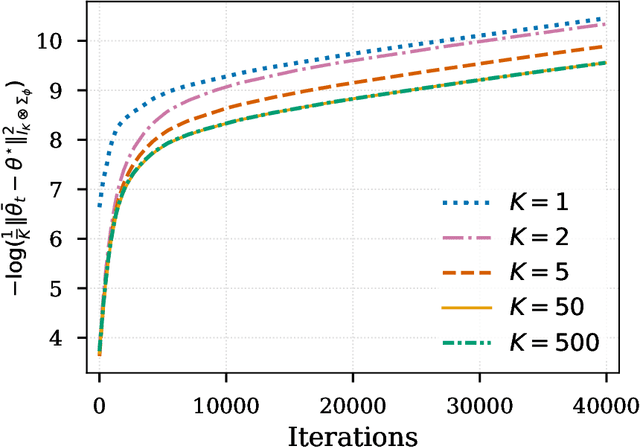


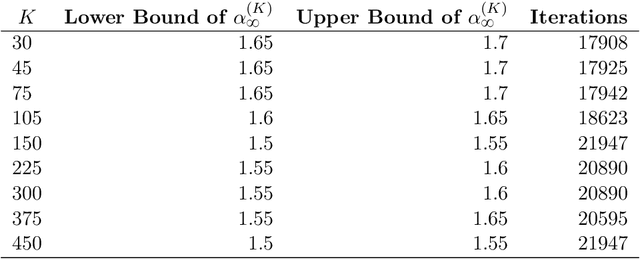
In this paper, we investigate the finite-sample statistical rates of distributional temporal difference (TD) learning with linear function approximation. The aim of distributional TD learning is to estimate the return distribution of a discounted Markov decision process for a given policy {\pi}. Prior works on statistical analysis of distributional TD learning mainly focus on the tabular case. In contrast, we first consider the linear function approximation setting and derive sharp finite-sample rates. Our theoretical results demonstrate that the sample complexity of linear distributional TD learning matches that of the classic linear TD learning. This implies that, with linear function approximation, learning the full distribution of the return using streaming data is no more difficult than learning its expectation (i.e. the value function). To derive tight sample complexity bounds, we conduct a fine-grained analysis of the linear-categorical Bellman equation, and employ the exponential stability arguments for products of random matrices. Our findings provide new insights into the statistical efficiency of distributional reinforcement learning algorithms.
A Regularized Online Newton Method for Stochastic Convex Bandits with Linear Vanishing Noise
Jan 19, 2025
We study a stochastic convex bandit problem where the subgaussian noise parameter is assumed to decrease linearly as the learner selects actions closer and closer to the minimizer of the convex loss function. Accordingly, we propose a Regularized Online Newton Method (RONM) for solving the problem, based on the Online Newton Method (ONM) of arXiv:2406.06506. Our RONM reaches a polylogarithmic regret in the time horizon $n$ when the loss function grows quadratically in the constraint set, which recovers the results of arXiv:2402.12042 in linear bandits. Our analyses rely on the growth rate of the precision matrix $\Sigma_t^{-1}$ in ONM and we find that linear growth solves the question exactly. These analyses also help us obtain better convergence rates when the loss function grows faster. We also study and analyze two new bandit models: stochastic convex bandits with noise scaled to a subgaussian parameter function and convex bandits with stochastic multiplicative noise.
Asymptotic Time-Uniform Inference for Parameters in Averaged Stochastic Approximation
Oct 19, 2024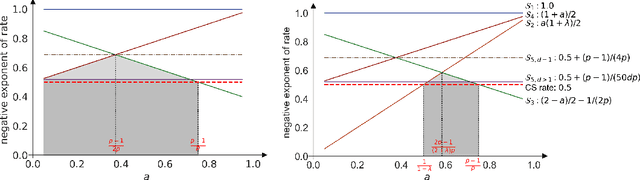

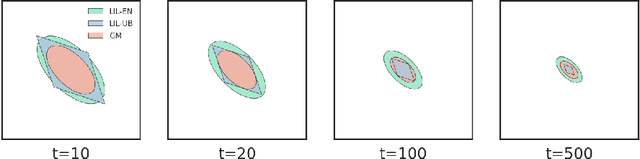
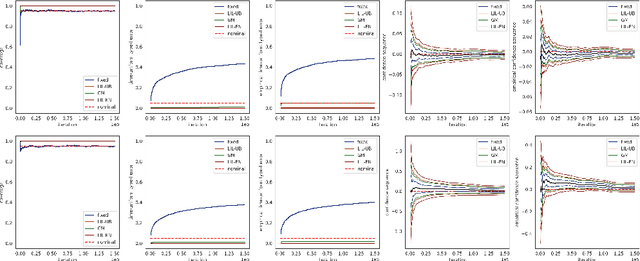
We study time-uniform statistical inference for parameters in stochastic approximation (SA), which encompasses a bunch of applications in optimization and machine learning. To that end, we analyze the almost-sure convergence rates of the averaged iterates to a scaled sum of Gaussians in both linear and nonlinear SA problems. We then construct three types of asymptotic confidence sequences that are valid uniformly across all times with coverage guarantees, in an asymptotic sense that the starting time is sufficiently large. These coverage guarantees remain valid if the unknown covariance matrix is replaced by its plug-in estimator, and we conduct experiments to validate our methodology.