 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Cross-Modal Salient Object Detection with U-Structure Networks
Paper and Code
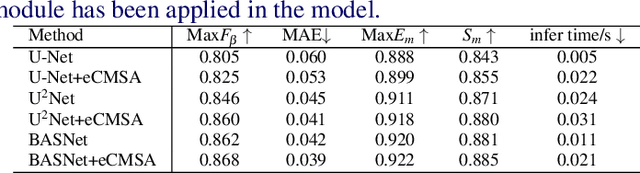

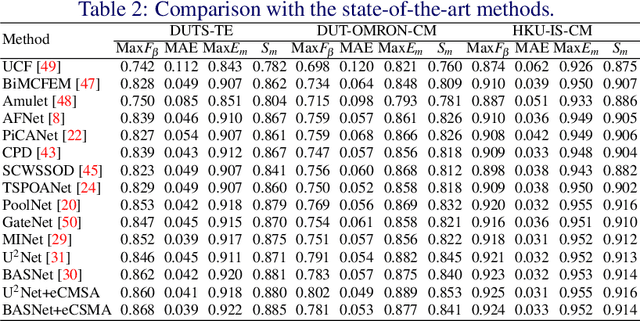
Salient Object Detection (SOD) is a popular and important topic aimed at precise detection and segmentation of the interesting regions in the images. We integrate the linguistic information into the vision-based U-Structure networks designed for salient object detection tasks. The experiments are based on the newly created DUTS Cross Modal (DUTS-CM) dataset, which contains both visual and linguistic labels. We propose a new module called efficient Cross-Modal Self-Attention (eCMSA) to combine visual and linguistic features and improve the performance of the original U-structure networks. Meanwhile, to reduce the heavy burden of labeling, we employ a semi-supervised learning method by training an image caption model based on the DUTS-CM dataset, which can automatically label other datasets like DUT-OMRON and HKU-IS. The comprehensive experiments show that the performance of SOD can be improved with the natural language input and is competitive compared with other SOD methods.