 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifying Robust Unlearning: Probing Residual Knowledge in Unlearned Models
Paper and Code
Apr 21, 2025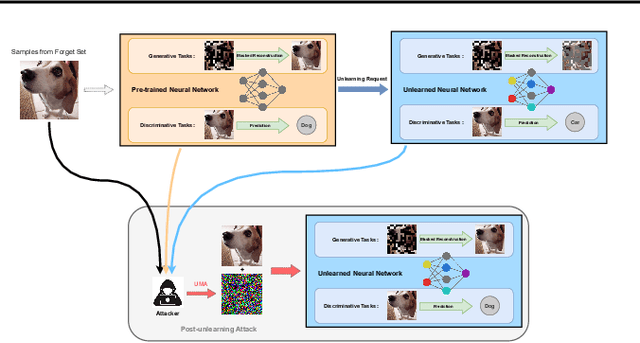
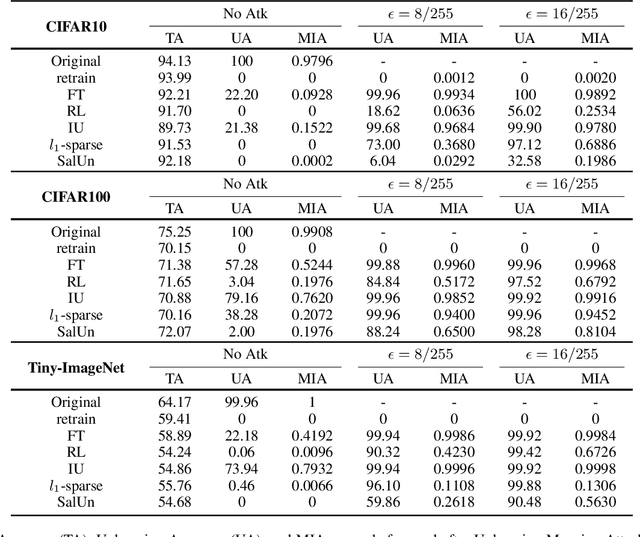
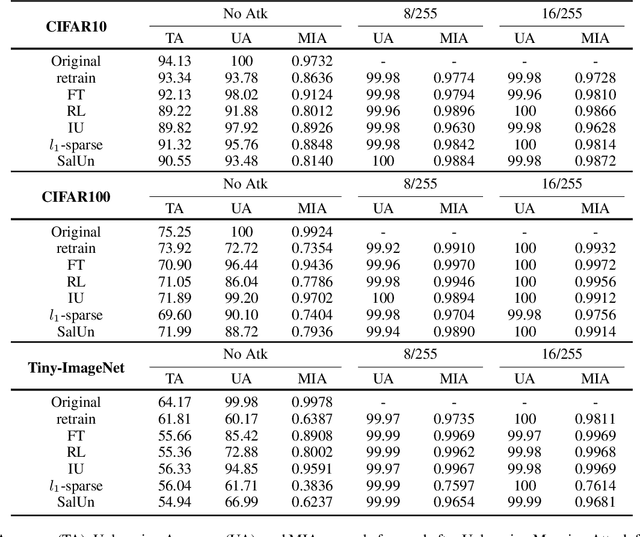

Machine Unlearning (MUL) is crucial for privacy protection and content regulation, yet recent studies reveal that traces of forgotten information persist in unlearned models, enabling adversaries to resurface removed knowledge. Existing verification methods only confirm whether unlearning was executed, failing to detect such residual information leaks. To address this, we introduce the concept of Robust Unlearning, ensuring models are indistinguishable from retraining and resistant to adversarial recovery. To empirically evaluate whether unlearning techniques meet this security standard, we propose the Unlearning Mapping Attack (UMA), a post-unlearning verification framework that actively probes models for forgotten traces using adversarial queries. Extensive experiments on discriminative and generative tasks show that existing unlearning techniques remain vulnerable, even when passing existing verification metrics. By establishing UMA as a practical verification tool, this study sets a new standard for assessing and enhancing machine unlearning security.