 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiDARTS: Improving DARTS by Node Normalization and Decorrelation Discretization
Paper and Code
Aug 25, 2021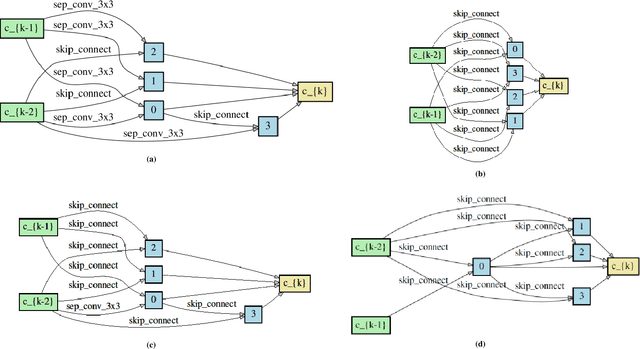

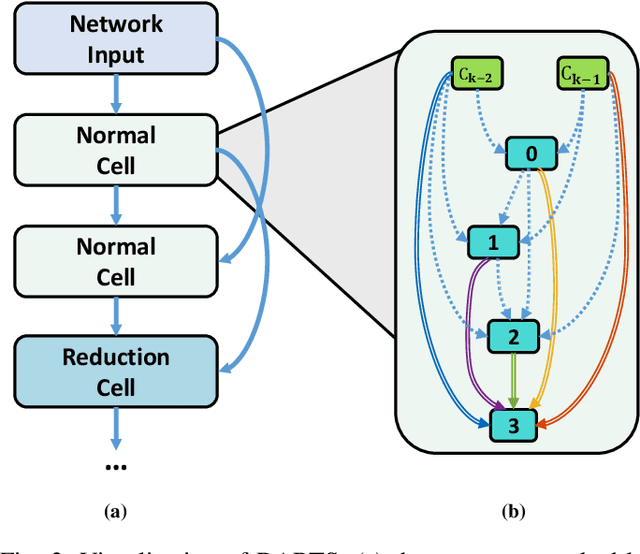

Differentiable ARchiTecture Search (DARTS) uses a continuous relaxation of network representation and dramatically accelerates Neural Architecture Search (NAS) by almost thousands of times in GPU-day. However, the searching process of DARTS is unstable, which suffers severe degradation when training epochs become large, thus limiting its application. In this paper, we claim that this degradation issue is caused by the imbalanced norms between different nodes and the highly correlated outputs from various operations. We then propose an improved version of DARTS, namely iDARTS, to deal with the two problems. In the training phase, it introduces node normalization to maintain the norm balance. In the discretization phase, the continuous architecture is approximated based on the similarity between the outputs of the node and the decorrelated operations rather than the values of the architecture parameters. Extensive evaluation is conducted on CIFAR-10 and ImageNet, and the error rates of 2.25\% and 24.7\% are reported within 0.2 and 1.9 GPU-day for architecture search respectively, which shows its effectiveness. Additional analysis also reveals that iDARTS has the advantage in robustness and generalization over other DARTS-based counterparts.