 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoL: Longer than Longer, Scaling Video Generation to Hour
Jan 23, 2026Recent research in long-form video generation has shifted from bidirectional to autoregressive models, yet these methods commonly suffer from error accumulation and a loss of long-term coherence. While attention sink frames have been introduced to mitigate this performance decay, they often induce a critical failure mode we term sink-collapse: the generated content repeatedly reverts to the sink frame, resulting in abrupt scene resets and cyclic motion patterns. Our analysis reveals that sink-collapse originates from an inherent conflict between the periodic structure of Rotary Position Embedding (RoPE) and the multi-head attention mechanisms prevalent in current generative models. To address it, we propose a lightweight, training-free approach that effectively suppresses this behavior by introducing multi-head RoPE jitter that breaks inter-head attention homogenization and mitigates long-horizon collapse. Extensive experiments show that our method successfully alleviates sink-collapse while preserving generation quality. To the best of our knowledge, this work achieves the first demonstration of real-time, streaming, and infinite-length video generation with little quality decay. As an illustration of this robustness, we generate continuous videos up to 12 hours in length, which, to our knowledge, is among the longest publicly demonstrated results in streaming video generation.
Reward-Forcing: Autoregressive Video Generation with Reward Feedback
Jan 23, 2026While most prior work in video generation relies on bidirectional architectures, recent efforts have sought to adapt these models into autoregressive variants to support near real-time generation. However, such adaptations often depend heavily on teacher models, which can limit performance, particularly in the absence of a strong autoregressive teacher, resulting in output quality that typically lags behind their bidirectional counterparts. In this paper, we explore an alternative approach that uses reward signals to guide the generation process, enabling more efficient and scalable autoregressive generation. By using reward signals to guide the model, our method simplifies training while preserving high visual fidelity and temporal consistency. Through extensive experiments on standard benchmarks, we find that our approach performs comparably to existing autoregressive models and, in some cases, surpasses similarly sized bidirectional models by avoiding constraints imposed by teacher architectures. For example, on VBench, our method achieves a total score of 84.92, closely matching state-of-the-art autoregressive methods that score 84.31 but require significant heterogeneous distillation.
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Oct 02, 2025Diffusion models have revolutionized image and video generation, achieving unprecedented visual quality. However, their reliance on transformer architectures incurs prohibitively high computational costs, particularly when extending generation to long videos. Recent work has explored autoregressive formulations for long video generation, typically by distilling from short-horizon bidirectional teachers. Nevertheless, given that teacher models cannot synthesize long videos, the extrapolation of student models beyond their training horizon often leads to pronounced quality degradation, arising from the compounding of errors within the continuous latent space. In this paper, we propose a simple yet effective approach to mitigate quality degradation in long-horizon video generation without requiring supervision from long-video teachers or retraining on long video datasets. Our approach centers on exploiting the rich knowledge of teacher models to provide guidance for the student model through sampled segments drawn from self-generated long videos. Our method maintains temporal consistency while scaling video length by up to 20x beyond teacher's capability, avoiding common issues such as over-exposure and error-accumulation without recomputing overlapping frames like previous methods. When scaling up the computation, our method shows the capability of generating videos up to 4 minutes and 15 seconds, equivalent to 99.9% of the maximum span supported by our base model's position embedding and more than 50x longer than that of our baseline model. Experiments on standard benchmarks and our proposed improved benchmark demonstrate that our approach substantially outperforms baseline methods in both fidelity and consistency. Our long-horizon videos demo can be found at https://self-forcing-plus-plus.github.io/
Understanding the Impact of Negative Prompts: When and How Do They Take Effect?
Jun 05, 2024



The concept of negative prompts, emerging from conditional generation models like Stable Diffusion, allows users to specify what to exclude from the generated images.%, demonstrating significant practical efficacy. Despite the widespread use of negative prompts, their intrinsic mechanisms remain largely unexplored. This paper presents the first comprehensive study to uncover how and when negative prompts take effect. Our extensive empirical analysis identifies two primary behaviors of negative prompts. Delayed Effect: The impact of negative prompts is observed after positive prompts render corresponding content. Deletion Through Neutralization: Negative prompts delete concepts from the generated image through a mutual cancellation effect in latent space with positive prompts. These insights reveal significant potential real-world applications; for example, we demonstrate that negative prompts can facilitate object inpainting with minimal alterations to the background via a simple adaptive algorithm. We believe our findings will offer valuable insights for the community in capitalizing on the potential of negative prompts.
The Crystal Ball Hypothesis in diffusion models: Anticipating object positions from initial noise
Jun 04, 2024



Diffusion models have achieved remarkable success in text-to-image generation tasks; however, the role of initial noise has been rarely explored. In this study, we identify specific regions within the initial noise image, termed trigger patches, that play a key role for object generation in the resulting images. Notably, these patches are ``universal'' and can be generalized across various positions, seeds, and prompts. To be specific, extracting these patches from one noise and injecting them into another noise leads to object generation in targeted areas. We identify these patches by analyzing the dispersion of object bounding boxes across generated images, leading to the development of a posterior analysis technique. Furthermore, we create a dataset consisting of Gaussian noises labeled with bounding boxes corresponding to the objects appearing in the generated images and train a detector that identifies these patches from the initial noise. To explain the formation of these patches, we reveal that they are outliers in Gaussian noise, and follow distinct distributions through two-sample tests. Finally, we find the misalignment between prompts and the trigger patch patterns can result in unsuccessful image generations. The study proposes a reject-sampling strategy to obtain optimal noise, aiming to improve prompt adherence and positional diversity in image generation.
Pre-trained Adversarial Perturbations
Oct 07, 2022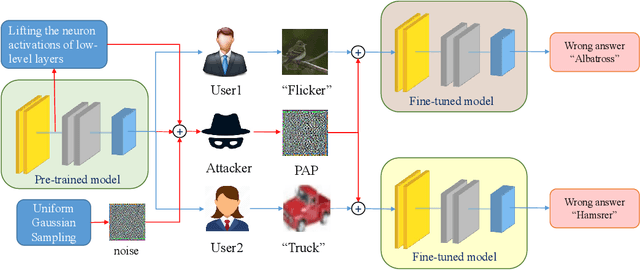
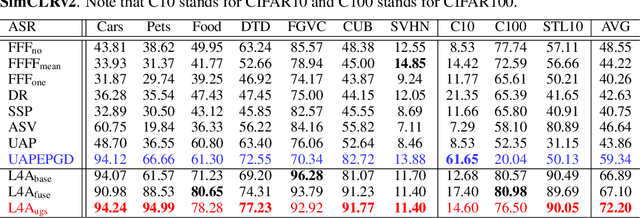
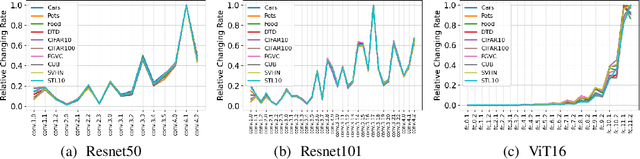
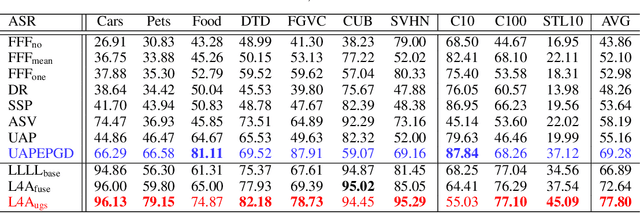
Self-supervised pre-training has drawn increasing attention in recent years due to its superior performance on numerous downstream tasks after fine-tuning. However, it is well-known that deep learning models lack the robustness to adversarial examples, which can also invoke security issues to pre-trained models, despite being less explored. In this paper, we delve into the robustness of pre-trained models by introducing Pre-trained Adversarial Perturbations (PAPs), which are universal perturbations crafted for the pre-trained models to maintain the effectiveness when attacking fine-tuned ones without any knowledge of the downstream tasks. To this end, we propose a Low-Level Layer Lifting Attack (L4A) method to generate effective PAPs by lifting the neuron activations of low-level layers of the pre-trained models. Equipped with an enhanced noise augmentation strategy, L4A is effective at generating more transferable PAPs against fine-tuned models. Extensive experiments on typical pre-trained vision models and ten downstream tasks demonstrate that our method improves the attack success rate by a large margin compared with state-of-the-art methods.