 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying Lens on Supervised Fine-Tuning Through Target Distribution Design
Jun 09, 2026Supervised fine-tuning (SFT) typically maximizes the likelihood of every token in a demonstrated trajectory. However, an observed token can be non-unique, noisy, or misaligned with the model prior. Strictly fitting toward this one-hot target may be suboptimal, especially when the pretrained model encodes a rich knowledge prior. In this work, we reinterpret SFT as target distribution design: instead of studying only the loss objective, we analyze the token-level target that the loss drives the model to match. We introduce the Q-target framework, which decomposes SFT supervision into two explicit choices: (1) how strongly to rely on the observed token, and (2) how to allocate the remaining probability mass over alternatives. This perspective unifies many existing SFT variants as implicit choices of the target distribution Q. Building on this view, we propose Target-SFT which constructs the training objective directly from the desired target distribution. This method consistently outperforms across the ten reasoning dataset-model settings evaluated, showing the effectiveness of this target-based approach. Overall, our formulation reveals a more fundamental design principle for SFT training and opens a broader search space for SFT objectives.
Cycle-Consistent Search: Question Reconstructability as a Proxy Reward for Search Agent Training
Apr 14, 2026Reinforcement Learning (RL) has shown strong potential for optimizing search agents in complex information retrieval tasks. However, existing approaches predominantly rely on gold supervision, such as ground-truth answers, which is difficult to scale. To address this limitation, we propose Cycle-Consistent Search (CCS), a gold-supervision-free framework for training search agents, inspired by cycle-consistency techniques from unsupervised machine translation and image-to-image translation. Our key hypothesis is that an optimal search trajectory, unlike insufficient or irrelevant ones, serves as a lossless encoding of the question's intent. Consequently, a high-quality trajectory should preserve the information required to accurately reconstruct the original question, thereby inducing a reward signal for policy optimization. However, naive cycle-consistency objectives are vulnerable to information leakage, as reconstruction may rely on superficial lexical cues rather than the underlying search process. To reduce this effect, we apply information bottlenecks, including exclusion of the final response and named entity recognition (NER) masking of search queries. These constraints force reconstruction to rely on retrieved observations together with the structural scaffold, ensuring that the resulting reward signal reflects informational adequacy rather than linguistic redundancy. Experiments on question-answering benchmarks show that CCS achieves performance comparable to supervised baselines while outperforming prior methods that do not rely on gold supervision. These results suggest that CCS provides a scalable training paradigm for training search agents in settings where gold supervision is unavailable.
FRESCO: Benchmarking and Optimizing Re-rankers for Evolving Semantic Conflict in Retrieval-Augmented Generation
Apr 14, 2026Retrieval-Augmented Generation (RAG) is a key approach to mitigating the temporal staleness of large language models (LLMs) by grounding responses in up-to-date evidence. Within the RAG pipeline, re-rankers play a pivotal role in selecting the most useful documents from retrieved candidates. However, existing benchmarks predominantly evaluate re-rankers in static settings and do not adequately assess performance under evolving information -- a critical gap, as real-world systems often must choose among temporally different pieces of evidence. To address this limitation, we introduce FRESCO (Factual Recency and Evolving Semantic COnflict), a benchmark for evaluating re-rankers in temporally dynamic contexts. By pairing recency-seeking queries with historical Wikipedia revisions, FRESCO tests whether re-rankers can prioritize factually recent evidence while maintaining semantic relevance. Our evaluation reveals a consistent failure mode across existing re-rankers: a strong bias toward older, semantically rich documents, even when they are factually obsolete. We further investigate an instruction optimization framework to mitigate this issue. By identifying Pareto-optimal instructions that balance Evolving and Non-Evolving Knowledge tasks, we obtain gains of up to 27% on Evolving Knowledge tasks while maintaining competitive performance on Non-Evolving Knowledge tasks.
T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
Mar 21, 2026While prior red-teaming efforts have focused on eliciting harmful text outputs from large language models (LLMs), such approaches fail to capture agent-specific vulnerabilities that emerge through multi-step tool execution, particularly in rapidly growing ecosystems such as the Model Context Protocol (MCP). To address this gap, we propose a trajectory-aware evolutionary search method, T-MAP, which leverages execution trajectories to guide the discovery of adversarial prompts. Our approach enables the automatic generation of attacks that not only bypass safety guardrails but also reliably realize harmful objectives through actual tool interactions. Empirical evaluations across diverse MCP environments demonstrate that T-MAP substantially outperforms baselines in attack realization rate (ARR) and remains effective against frontier models, including GPT-5.2, Gemini-3-Pro, Qwen3.5, and GLM-5, thereby revealing previously underexplored vulnerabilities in autonomous LLM agents.
DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
Oct 16, 2025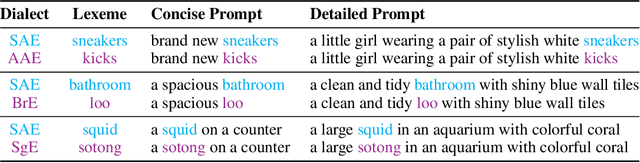
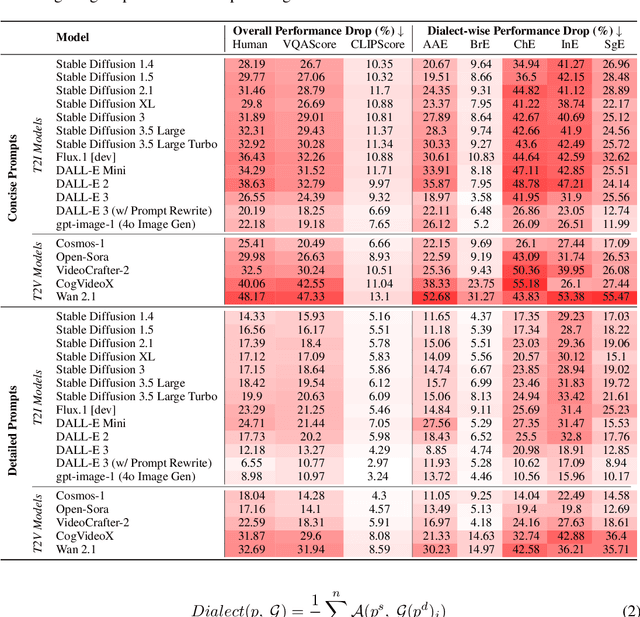
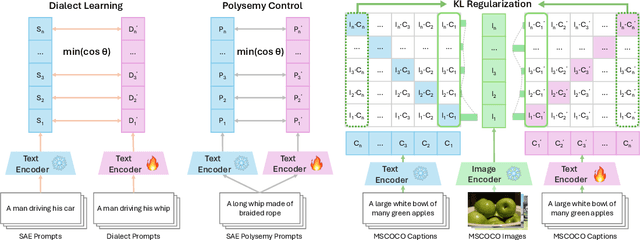
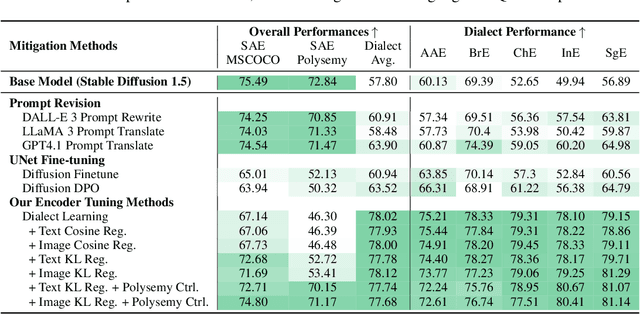
Contact languages like English exhibit rich regional variations in the form of dialects, which are often used by dialect speakers interacting with generative models. However, can multimodal generative models effectively produce content given dialectal textual input? In this work, we study this question by constructing a new large-scale benchmark spanning six common English dialects. We work with dialect speakers to collect and verify over 4200 unique prompts and evaluate on 17 image and video generative models. Our automatic and human evaluation results show that current state-of-the-art multimodal generative models exhibit 32.26% to 48.17% performance degradation when a single dialect word is used in the prompt. Common mitigation methods such as fine-tuning and prompt rewriting can only improve dialect performance by small margins (< 7%), while potentially incurring significant performance degradation in Standard American English (SAE). To this end, we design a general encoder-based mitigation strategy for multimodal generative models. Our method teaches the model to recognize new dialect features while preserving SAE performance. Experiments on models such as Stable Diffusion 1.5 show that our method is able to simultaneously raise performance on five dialects to be on par with SAE (+34.4%), while incurring near zero cost to SAE performance.
Don't Think Longer, Think Wisely: Optimizing Thinking Dynamics for Large Reasoning Models
May 27, 2025While recent success of large reasoning models (LRMs) significantly advanced LLMs' reasoning capability by optimizing the final answer accuracy using reinforcement learning, they may also drastically increase the output length due to overthinking, characterized by unnecessarily complex reasoning paths that waste computation and potentially degrade the performance. We hypothesize that such inefficiencies stem from LRMs' limited capability to dynamically select the proper modular reasoning strategies, termed thinking patterns at the right position. To investigate this hypothesis, we propose a dynamic optimization framework that segments model-generated reasoning paths into distinct thinking patterns, systematically identifying and promoting beneficial patterns that improve the answer while removing detrimental ones. Empirical analysis confirms that our optimized thinking paths yield more concise yet sufficiently informative trajectories, enhancing reasoning efficiency by reducing attention FLOPs by up to 47% while maintaining accuracy for originally correct responses. Moreover, a non-trivial portion of originally incorrect responses are transformed into correct ones, achieving a 15.6% accuracy improvement with reduced length. Motivated by the improvement brought by the optimized thinking paths, we apply a preference optimization technique supported by a pairwise dataset contrasting suboptimal and optimal reasoning paths. Experimental evaluations across multiple mathematical reasoning benchmarks reveal that our method notably reduces computational overhead while simultaneously improving reasoning accuracy, achieving up to a 12% accuracy improvement and reducing token usage from approximately 5,000 to 3,000 tokens.
One Prompt is not Enough: Automated Construction of a Mixture-of-Expert Prompts
Jun 28, 2024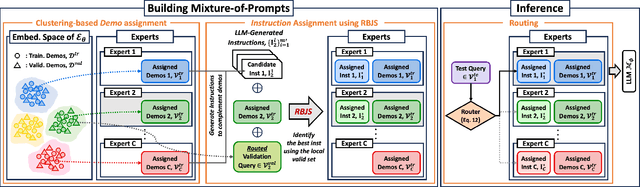
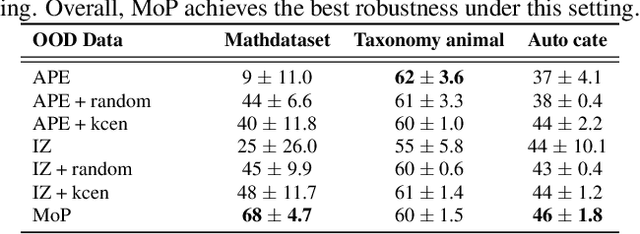
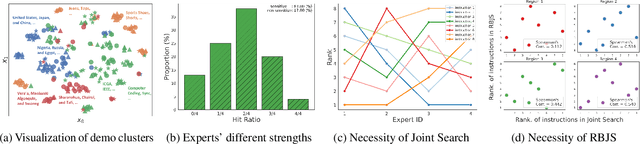
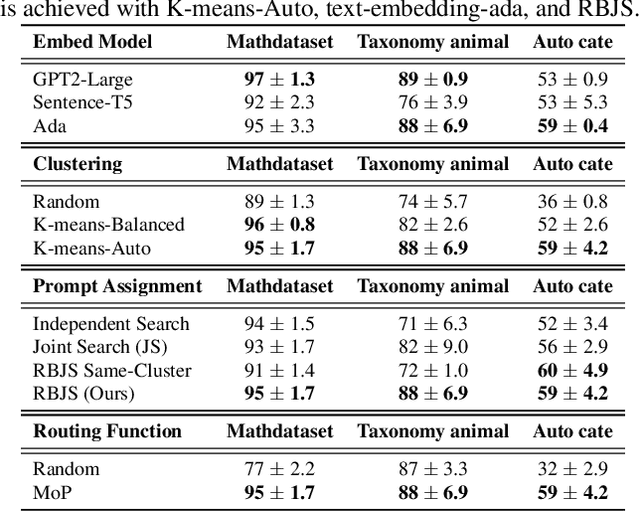
Large Language Models (LLMs) exhibit strong generalization capabilities to novel tasks when prompted with language instructions and in-context demos. Since this ability sensitively depends on the quality of prompts, various methods have been explored to automate the instruction design. While these methods demonstrated promising results, they also restricted the searched prompt to one instruction. Such simplification significantly limits their capacity, as a single demo-free instruction might not be able to cover the entire complex problem space of the targeted task. To alleviate this issue, we adopt the Mixture-of-Expert paradigm and divide the problem space into a set of sub-regions; Each sub-region is governed by a specialized expert, equipped with both an instruction and a set of demos. A two-phase process is developed to construct the specialized expert for each region: (1) demo assignment: Inspired by the theoretical connection between in-context learning and kernel regression, we group demos into experts based on their semantic similarity; (2) instruction assignment: A region-based joint search of an instruction per expert complements the demos assigned to it, yielding a synergistic effect. The resulting method, codenamed Mixture-of-Prompts (MoP), achieves an average win rate of 81% against prior arts across several major benchmarks.
* ICML 2024. code available at https://github.com/ruocwang/mixture-of-prompts
Meta-prediction Model for Distillation-Aware NAS on Unseen Datasets
May 26, 2023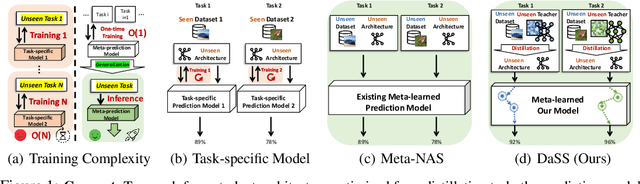
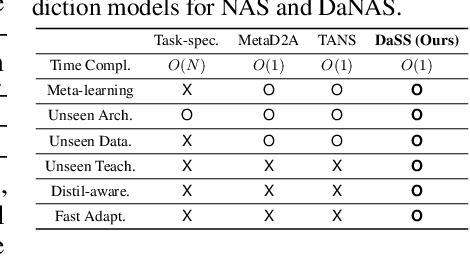
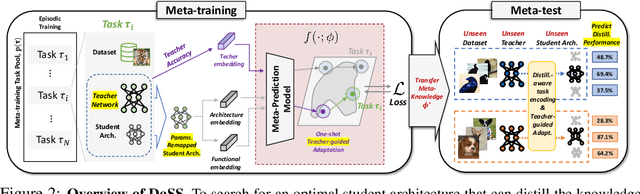
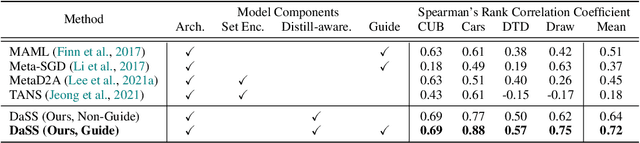
Distillation-aware Neural Architecture Search (DaNAS) aims to search for an optimal student architecture that obtains the best performance and/or efficiency when distilling the knowledge from a given teacher model. Previous DaNAS methods have mostly tackled the search for the neural architecture for fixed datasets and the teacher, which are not generalized well on a new task consisting of an unseen dataset and an unseen teacher, thus need to perform a costly search for any new combination of the datasets and the teachers. For standard NAS tasks without KD, meta-learning-based computationally efficient NAS methods have been proposed, which learn the generalized search process over multiple tasks (datasets) and transfer the knowledge obtained over those tasks to a new task. However, since they assume learning from scratch without KD from a teacher, they might not be ideal for DaNAS scenarios. To eliminate the excessive computational cost of DaNAS methods and the sub-optimality of rapid NAS methods, we propose a distillation-aware meta accuracy prediction model, DaSS (Distillation-aware Student Search), which can predict a given architecture's final performances on a dataset when performing KD with a given teacher, without having actually to train it on the target task. The experimental results demonstrate that our proposed meta-prediction model successfully generalizes to multiple unseen datasets for DaNAS tasks, largely outperforming existing meta-NAS methods and rapid NAS baselines. Code is available at https://github.com/CownowAn/DaSS
DiffusionNAG: Task-guided Neural Architecture Generation with Diffusion Models
May 26, 2023



Neural Architecture Search (NAS) has emerged as a powerful technique for automating neural architecture design. However, existing NAS methods either require an excessive amount of time for repetitive training or sampling of many task-irrelevant architectures. Moreover, they lack generalization across different tasks and usually require searching for optimal architectures for each task from scratch without reusing the knowledge from the previous NAS tasks. To tackle such limitations of existing NAS methods, we propose a novel transferable task-guided Neural Architecture Generation (NAG) framework based on diffusion models, dubbed DiffusionNAG. With the guidance of a surrogate model, such as a performance predictor for a given task, our DiffusionNAG can generate task-optimal architectures for diverse tasks, including unseen tasks. DiffusionNAG is highly efficient as it generates task-optimal neural architectures by leveraging the prior knowledge obtained from the previous tasks and neural architecture distribution. Furthermore, we introduce a score network to ensure the generation of valid architectures represented as directed acyclic graphs, unlike existing graph generative models that focus on generating undirected graphs. Extensive experiments demonstrate that DiffusionNAG significantly outperforms the state-of-the-art transferable NAG model in architecture generation quality, as well as previous NAS methods on four computer vision datasets with largely reduced computational cost.