 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Reward Hacking in Text-to-Image Reinforcement Learning
Jan 06, 2026Reinforcement learning (RL) has become a standard approach for post-training large language models and, more recently, for improving image generation models, which uses reward functions to enhance generation quality and human preference alignment. However, existing reward designs are often imperfect proxies for true human judgment, making models prone to reward hacking--producing unrealistic or low-quality images that nevertheless achieve high reward scores. In this work, we systematically analyze reward hacking behaviors in text-to-image (T2I) RL post-training. We investigate how both aesthetic/human preference rewards and prompt-image consistency rewards individually contribute to reward hacking and further show that ensembling multiple rewards can only partially mitigate this issue. Across diverse reward models, we identify a common failure mode: the generation of artifact-prone images. To address this, we propose a lightweight and adaptive artifact reward model, trained on a small curated dataset of artifact-free and artifact-containing samples. This model can be integrated into existing RL pipelines as an effective regularizer for commonly used reward models. Experiments demonstrate that incorporating our artifact reward significantly improves visual realism and reduces reward hacking across multiple T2I RL setups, demonstrating the effectiveness of lightweight reward augment serving as a safeguard against reward hacking.
Enhancing CLIP Conceptual Embedding through Knowledge Distillation
Dec 07, 2024

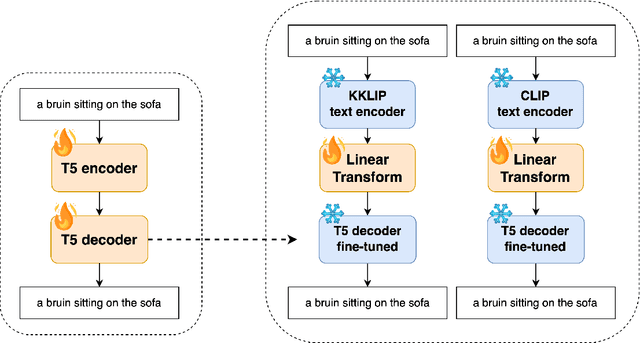
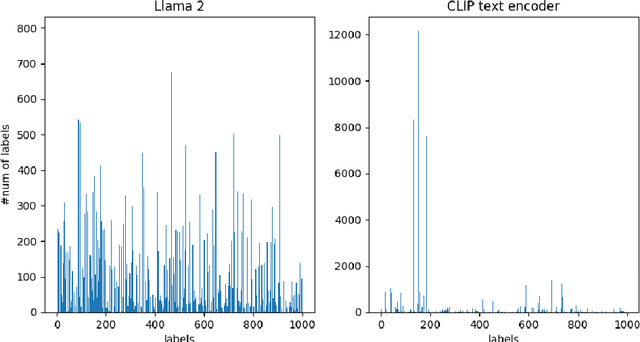
Recently, CLIP has become an important model for aligning images and text in multi-modal contexts. However, researchers have identified limitations in the ability of CLIP's text and image encoders to extract detailed knowledge from pairs of captions and images. In response, this paper presents Knowledge-CLIP, an innovative approach designed to improve CLIP's performance by integrating a new knowledge distillation (KD) method based on Llama 2. Our approach focuses on three key objectives: Text Embedding Distillation, Concept Learning, and Contrastive Learning. First, Text Embedding Distillation involves training the Knowledge-CLIP text encoder to mirror the teacher model, Llama 2. Next, Concept Learning assigns a soft concept label to each caption-image pair by employing offline K-means clustering on text data from Llama 2, enabling Knowledge-CLIP to learn from these soft concept labels. Lastly, Contrastive Learning aligns the text and image embeddings. Our experimental findings show that the proposed model improves the performance of both text and image encoders.
KKLIP: Knowledge Distillation Exploiting K-means Clustering for Language-Image Pre-Training
Dec 04, 2024Recently, CLIP has emerged as a valuable model for aligning image and text information in multi-modal scenarios. However, researchers have observed limitations in the ability of CLIP's text and image encoders to extract detailed knowledge from caption-image pairs. In response, this paper introduces KKLIP, a novel approach designed to enhance the quality of CLIP by incorporating a new knowledge distillation (KD) method derived from Llama 2. Our method comprises three objectives: Text Embedding Distillation, Concept Learning, and Contrastive Learning. Firstly, Text Embedding Distillation involves training the KKLIP text encoder to emulate the teacher model, Llama 2. Secondly, Concept Learning assigns a soft concept label to each caption-image pair through offline k-means clustering of text information from Llama 2, allowing KKLIP to learn from these soft concept labels. Finally, Contrastive Learning harmonizes text and image embeddings. Our experimental results demonstrate that KKLIP enhances the quality of both text and image encoders.
Solving for X and Beyond: Can Large Language Models Solve Complex Math Problems with More-Than-Two Unknowns?
Jul 06, 2024Large Language Models (LLMs) have demonstrated remarkable performance in solving math problems, a hallmark of human intelligence. Despite high success rates on current benchmarks; however, these often feature simple problems with only one or two unknowns, which do not sufficiently challenge their reasoning capacities. This paper introduces a novel benchmark, BeyondX, designed to address these limitations by incorporating problems with multiple unknowns. Recognizing the challenges in proposing multi-unknown problems from scratch, we developed BeyondX using an innovative automated pipeline that progressively increases complexity by expanding the number of unknowns in simpler problems. Empirical study on BeyondX reveals that the performance of existing LLMs, even those fine-tuned specifically on math tasks, significantly decreases as the number of unknowns increases - with a performance drop of up to 70\% observed in GPT-4. To tackle these challenges, we propose the Formulate-and-Solve strategy, a generalized prompting approach that effectively handles problems with an arbitrary number of unknowns. Our findings reveal that this strategy not only enhances LLM performance on the BeyondX benchmark but also provides deeper insights into the computational limits of LLMs when faced with more complex mathematical challenges.