 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing CLIP Conceptual Embedding through Knowledge Distillation
Paper and Code
Dec 07, 2024

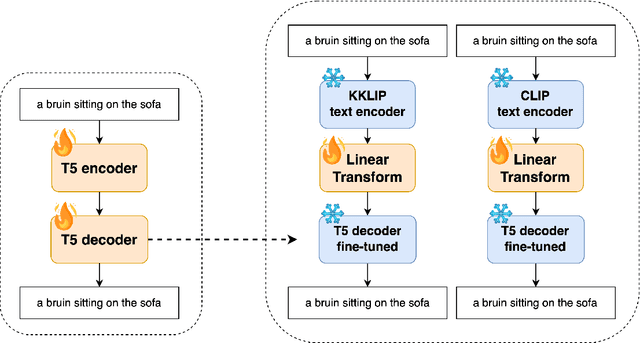
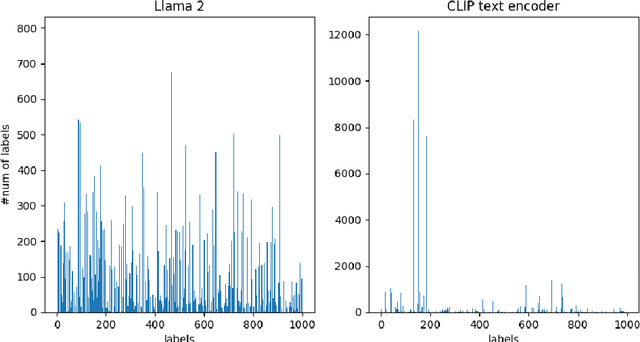
Recently, CLIP has become an important model for aligning images and text in multi-modal contexts. However, researchers have identified limitations in the ability of CLIP's text and image encoders to extract detailed knowledge from pairs of captions and images. In response, this paper presents Knowledge-CLIP, an innovative approach designed to improve CLIP's performance by integrating a new knowledge distillation (KD) method based on Llama 2. Our approach focuses on three key objectives: Text Embedding Distillation, Concept Learning, and Contrastive Learning. First, Text Embedding Distillation involves training the Knowledge-CLIP text encoder to mirror the teacher model, Llama 2. Next, Concept Learning assigns a soft concept label to each caption-image pair by employing offline K-means clustering on text data from Llama 2, enabling Knowledge-CLIP to learn from these soft concept labels. Lastly, Contrastive Learning aligns the text and image embeddings. Our experimental findings show that the proposed model improves the performance of both text and image encoders.