 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Primal-dual Methods for Regularized Markov Decision Processes
Feb 21, 2022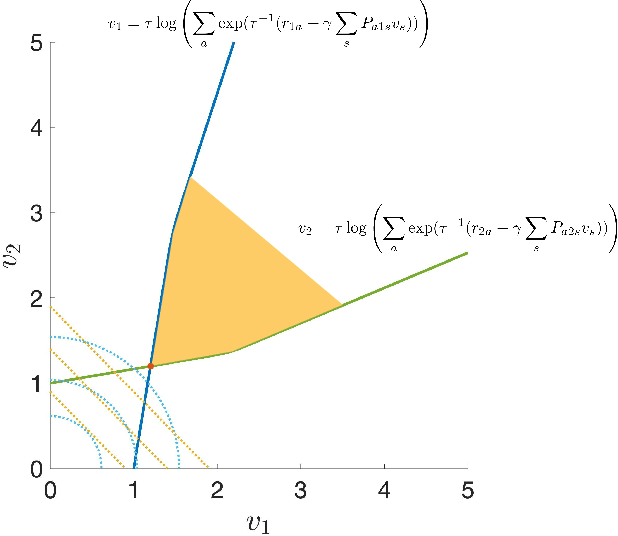
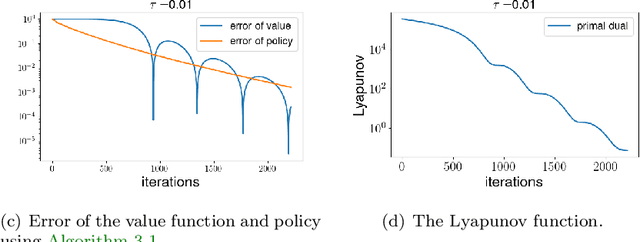
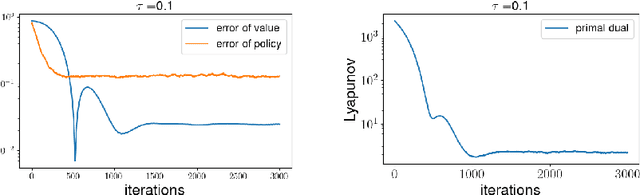
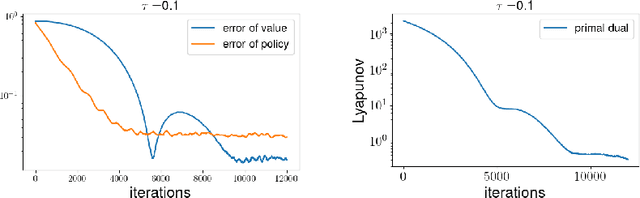
Entropy regularized Markov decision processes have been widely used in reinforcement learning. This paper is concerned with the primal-dual formulation of the entropy regularized problems. Standard first-order methods suffer from slow convergence due to the lack of strict convexity and concavity. To address this issue, we first introduce a new quadratically convexified primal-dual formulation. The natural gradient ascent descent of the new formulation enjoys global convergence guarantee and exponential convergence rate. We also propose a new interpolating metric that further accelerates the convergence significantly. Numerical results are provided to demonstrate the performance of the proposed methods under multiple settings.
Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Oct 01, 2021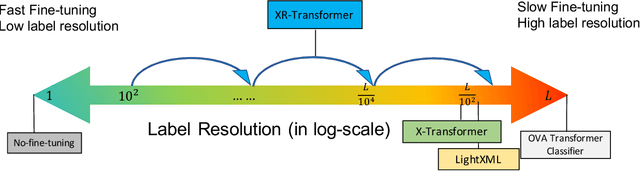
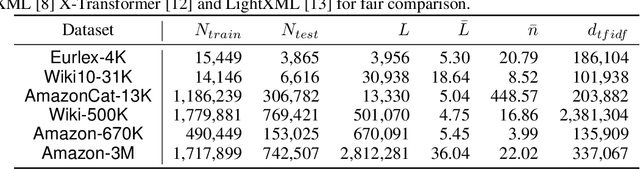
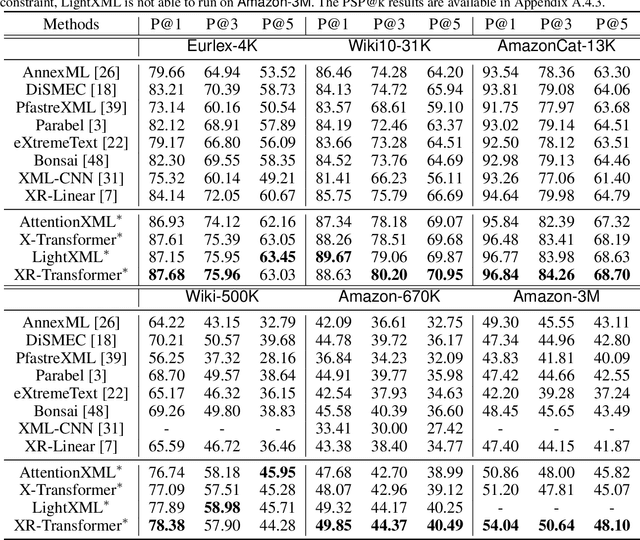

Extreme multi-label text classification (XMC) seeks to find relevant labels from an extreme large label collection for a given text input. Many real-world applications can be formulated as XMC problems, such as recommendation systems, document tagging and semantic search. Recently, transformer based XMC methods, such as X-Transformer and LightXML, have shown significant improvement over other XMC methods. Despite leveraging pre-trained transformer models for text representation, the fine-tuning procedure of transformer models on large label space still has lengthy computational time even with powerful GPUs. In this paper, we propose a novel recursive approach, XR-Transformer to accelerate the procedure through recursively fine-tuning transformer models on a series of multi-resolution objectives related to the original XMC objective function. Empirical results show that XR-Transformer takes significantly less training time compared to other transformer-based XMC models while yielding better state-of-the-art results. In particular, on the public Amazon-3M dataset with 3 million labels, XR-Transformer is not only 20x faster than X-Transformer but also improves the Precision@1 from 51% to 54%.
Extreme Multi-label Classification from Aggregated Labels
Apr 01, 2020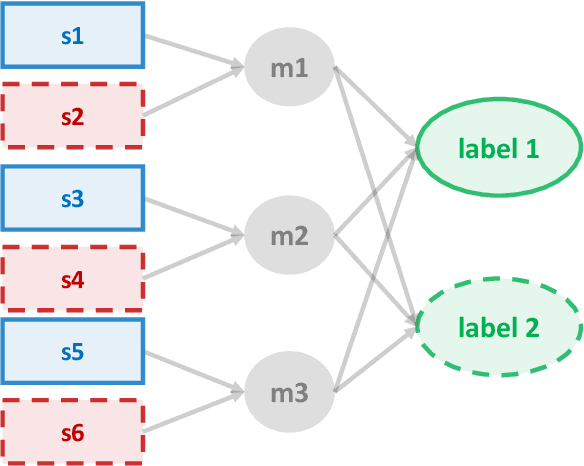

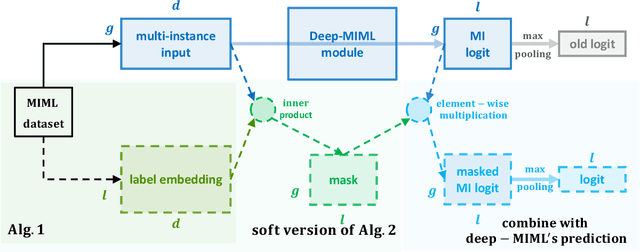
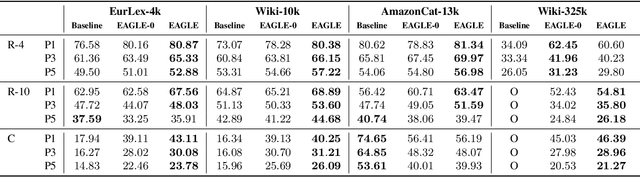
Extreme multi-label classification (XMC) is the problem of finding the relevant labels for an input, from a very large universe of possible labels. We consider XMC in the setting where labels are available only for groups of samples - but not for individual ones. Current XMC approaches are not built for such multi-instance multi-label (MIML) training data, and MIML approaches do not scale to XMC sizes. We develop a new and scalable algorithm to impute individual-sample labels from the group labels; this can be paired with any existing XMC method to solve the aggregated label problem. We characterize the statistical properties of our algorithm under mild assumptions, and provide a new end-to-end framework for MIML as an extension. Experiments on both aggregated label XMC and MIML tasks show the advantages over existing approaches.
AutoAssist: A Framework to Accelerate Training of Deep Neural Networks
May 08, 2019



Deep neural networks have yielded superior performance in many applications; however, the gradient computation in a deep model with millions of instances lead to a lengthy training process even with modern GPU/TPU hardware acceleration. In this paper, we propose AutoAssist, a simple framework to accelerate training of a deep neural network. Typically, as the training procedure evolves, the amount of improvement in the current model by a stochastic gradient update on each instance varies dynamically. In AutoAssist, we utilize this fact and design a simple instance shrinking operation, which is used to filter out instances with relatively low marginal improvement to the current model; thus the computationally intensive gradient computations are performed on informative instances as much as possible. We prove that the proposed technique outperforms vanilla SGD with existing importance sampling approaches for linear SVM problems, and establish an O(1/k) convergence for strongly convex problems. In order to apply the proposed techniques to accelerate training of deep models, we propose to jointly train a very lightweight Assistant network in addition to the original deep network referred to as Boss. The Assistant network is designed to gauge the importance of a given instance with respect to the current Boss such that a shrinking operation can be applied in the batch generator. With careful design, we train the Boss and Assistant in a nonblocking and asynchronous fashion such that overhead is minimal. We demonstrate that AutoAssist reduces the number of epochs by 40% for training a ResNet to reach the same test accuracy on an image classification data set and saves 30% training time needed for a transformer model to yield the same BLEU scores on a translation dataset.