 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASER: Attention with Exponential Transformation
Paper and Code
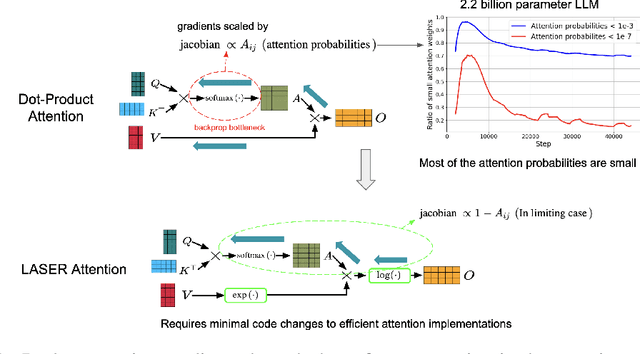

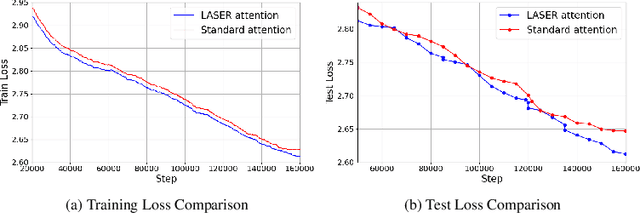
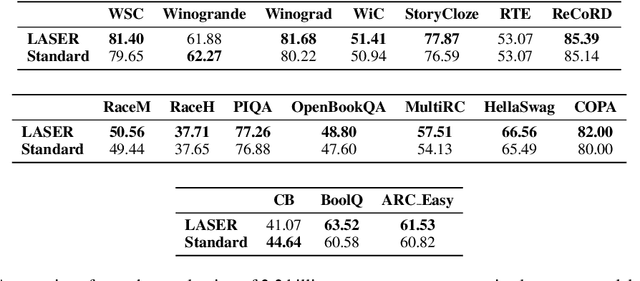
Transformers have had tremendous impact for several sequence related tasks, largely due to their ability to retrieve from any part of the sequence via softmax based dot-product attention. This mechanism plays a crucial role in Transformer's performance. We analyze the gradients backpropagated through the softmax operation in the attention mechanism and observe that these gradients can often be small. This poor gradient signal backpropagation can lead to inefficient learning of parameters preceeding the attention operations. To this end, we introduce a new attention mechanism called LASER, which we analytically show to admit a larger gradient signal. We show that LASER Attention can be implemented by making small modifications to existing attention implementations. We conduct experiments on autoregressive large language models (LLMs) with upto 2.2 billion parameters where we show upto 3.38% and an average of ~1% improvement over standard attention on downstream evaluations. Using LASER gives the following relative improvements in generalization performance across a variety of tasks (vision, text and speech): 4.67% accuracy in Vision Transformer (ViT) on Imagenet, 2.25% error rate in Conformer on the Librispeech speech-to-text and 0.93% fraction of incorrect predictions in BERT with 2.2 billion parameters.